|
Опрос
|
реклама
Быстрый переход
Anthropic ведёт переговоры с Samsung о создании собственного ИИ-чипа
02.07.2026 [19:59],
Сергей Сурабекянц
Осведомлённые источники сообщили о переговорах между американским разработчиком больших языковых моделей искусственного интеллекта Anthropic и южнокорейским полупроводниковым гигантом Samsung Electronics о партнёрстве с целью выпуска фирменного ускорителя искусственного интеллекта Anthropic. 
Источник изображения: Anthropic По словам инсайдеров, планы Anthropic находятся на ранней стадии — компания пытается определиться с архитектурой, специализацией и мощностью потенциального ускорителя. Компания отказалась комментировать слухи о переговорах с Samsung, заявив, что чип Trainium от Amazon, тензорные процессоры Google и графические процессоры Nvidia остаются центральными элементами вычислительной стратегии Anthropic. Samsung также отказалась от комментариев. Компании, занимающиеся искусственным интеллектом, стремятся диверсифицировать поставки чипов, чтобы удовлетворить растущий спрос на свои услуги. В прошлом месяце компания OpenAI совместно с Broadcom представила свой первый специализированный ускоритель искусственного интеллекта, ориентированный на запуск уже готовых моделей. По замыслу компании, выпуск собственного чипа повысит эффективность работы оборудования, необходимого для работы её моделей. Qualcomm ударила по Nvidia, объявив о выпуске Arm-процессора Dragonfly C1000 на ядрах Oryon и других чипов для дата-центров
25.06.2026 [10:16],
Павел Котов
В рамках мероприятия Investor Day компания Qualcomm рассказала о своих планах в отношении оборудования для центров обработки данных с системами искусственного интеллекта. Наиболее примечательными продуктами стали серверный процессор Qualcomm Dragonfly C1000, технология High Bandwidth Compute (HBC), ускоритель Qualcomm Dragonfly AI300, сетевые решения и разработка чипов на заказ. 
Источник изображений: qualcomm.com Основным направлением технологий ИИ сегодня являются агенты, которые не просто отвечают на запросы аналогично чат-ботам, а выполняют действия от имени пользователей. Для работы ИИ-агентов требуется оборудование нового типа, и у Qualcomm подготовлены необходимые решения.  Главным элементом новой линейки стал серверный процессор Qualcomm Dragonfly C1000 на фирменных ядрах Oryon с поддержкой тактовых частот выше 5 ГГц — располагая чиплетной компоновкой, один такой процессор может содержать более 250 ядер. Компания обещает более чем двухкратный прирост производительности на ватт по сравнению с существующими решениями; тесная интеграция с памятью и ускорителями обеспечивается при помощи интерфейсов CXL и PCIe 7.0. Процессоры Qualcomm Dragonfly C1000 выйдут на рынок в 2028 году.  Технология Qualcomm High Bandwidth Compute воплощает концепцию «близкой к памяти» вычислительной архитектуры (near-memory computing), предусматривающей размещение памяти и вычислительных блоков в единой трёхмерной структуре, что помогает преодолеть ограничения, связанные с пропускной способностью памяти. Производитель обещает повысить скорость памяти по сравнению с HBM и LPDDR, а также увеличить её энергоэффективность. Ускоритель Qualcomm Dragonfly AI250 (выйдет в 2027 году) на основе памяти HBC Gen 1 обещает 18-кратный прирост производительности в сравнении с основанным LPDDR5X ускорителем Dragonfly AI200. У AI300 (появится в 2028 году) на основе HBC Gen 2 прирост производительности по сравнению с тем же компонентом обещает быть 54-кратным.  Ускоритель Qualcomm Dragonfly AI300 на основе технологии HBC второго поколения предназначен для инференса больших языковых и мультимодальных моделей. По сравнению с современными архитектурами на основе графических процессоров компания обещает кратный рост эффективности на ватт, особенно в задачах, где важны высокая пропускная способность памяти и низкие задержки. Важным направлением платформы Qualcomm Dragonfly является комплект сетевых решений для подключения и передачи данных: компания предлагает интерфейсы класса 800G и 1.6T, а также оптические и медные каналы связи, способные работать на расстояниях до 20 км. Qualcomm изъявила готовность адаптировать свои решения под нужды конкретных облачных провайдеров. Речь идёт о сборке инфраструктуры ЦОД как модульного конструктора: центральные процессоры, ускорители, память и сетевые решения проектируются под конкретные рабочие нагрузки. Это помогает гиперскейлерам оптимизировать показатели производительности, энергопотребления и стоимости владения. Первым крупным клиентом Qualcomm стала компания Meta✴✴, с которой чипмейкер заключил многолетнее соглашение. В рамках соглашения в обновлённой серверной инфраструктуре гиганта соцсетей будут использоваться серверные процессоры Dragonfly C1000. OpenAI представила свой дебютный чип Jalapeno — он сулит удешевление работы ChatGPT
24.06.2026 [17:56],
Сергей Сурабекянц
Сегодня OpenAI сообщила о готовности первых образцов специализированного чипа Jalapeno для запуска уже обученных ИИ-моделей (инференса) и начале его тестирования. Компания рассчитывает получить дополнительное конкурентное преимущество за счёт адаптации оборудования под свои продукты. Чип создан в партнёрстве с Broadcom. По словам главы Broadcom Хока Тана (Hock Tan), он позволит сэкономить до 50 % ресурсов по сравнению с типичными графическими процессорами. 
Источник изображения: OpenAI В октябре OpenAI объявила о партнёрстве с Broadcom для разработки ускорителей, оптимизированных для работы с её моделями искусственного интеллекта. По словам OpenAI и Broadcom, новые чипы были разработаны с нуля в рекордно короткие сроки и способны обеспечить производительность на ватт энергии, которая «значительно превосходит современные аналоги» в инференсе. Финальные версии чипов будут использоваться в крупных дата-центрах Microsoft и других партнёров OpenAI, начиная с конца этого года. Чипы призваны повысить производительность ИИ-моделей за счёт уменьшения объёма передаваемых данных. Они разработаны с учётом особенностей использования вычислительных ресурсов, памяти и сетевого оборудования, наиболее важных для высококлассных моделей ИИ. Следующая версия Jalapeno запланирована на 2028 год. Партнёры не исключают появления в будущем чипов, рассчитанных на другие рабочие нагрузки. Тан ожидает, что OpenAI и Broadcom смогут превзойти его предыдущий прогноз по развёртыванию чипов искусственного интеллекта общей мощностью 1,3 ГВт в следующем году. «Мы хотим верить, что сможем добиться лучших результатов, потому что спрос очень высок», — заявил он. Глава подразделения аппаратного обеспечения OpenAI Ричард Хо (Richard Ho), отказался раскрыть механизм взаиморасчётов с Broadcom, отметив, что финансовые соглашения будут окончательно согласованы после полного выполнения заказа на чипы. Тан также отказался от комментариев, но подтвердил, что Broadcom создала механизм финансирования разработки чипов совместно с инвестиционными компаниями Apollo Global Management и Blackstone. C начала этого года OpenAI привлекла уже $122 млрд инвестиций для поддержки своих дорогостоящих проектов по разработке чипов, центров обработки данных и привлечению талантливых сотрудников. Затраты на разработку и выпуск собственных чипов увеличат и без того огромные расходы убыточного стартапа на физическую инфраструктуру для поддержки ИИ. Акции Broadcom после анонса процессора OpenAI выросли на 1,6 % до $386,25. С начала года они подорожали почти на 10 %. «Сбер» встал в очередь за китайскими чипами для «ГигаЧата» — перед ним ByteDance и Alibaba
20.05.2026 [18:44],
Сергей Сурабекянц
Глава «Сбера» Герман Греф заявил, что крупнейший российский банк надеется использовать процессоры китайского производства для работы флагманской модели искусственного интеллекта «ГигаЧат». Это заявление Грефа прозвучало в эфире «Первого канала» во время двухдневного визита Владимира Путина в Пекин, на фоне западных санкций, которые препятствуют российским закупкам передового иностранного оборудования для ИИ. 
Источник изображения: Huawei Греф не уточнил, какие именно китайские чипы интересуют «Сбер», но наиболее вероятным кандидатом является семейство Ascend 950 от Huawei, которое стало объектом ожесточённой конкуренции среди китайских технологических гигантов. Запрос от «Сбера», несомненно, создаст дополнительные сложности для Huawei, которая должна выполнить огромные заказы от ByteDance, Alibaba и Tencent. Только ByteDance в начале этого года заказала чипов Ascend 950PR на сумму $5,6 млрд. Huawei планирует выпустить 750 000 процессоров 950PR в 2026 году, но производство на SMIC ограничено низким выходом годных изделий на 7-нм техпроцессе DUV и предполагаемым восьмимесячным циклом от начала производства до готового процессора. По производительности в режиме инференса 950PR находится между Nvidia H100 и H200 и, по заявлению производителя, превосходит ограниченный H20 в 2,8 раза, хотя эта цифра не поддаётся прямой проверке, поскольку чипы H20 не имеют встроенной поддержки FP4. Тем не менее, каждый чип, который Huawei может произвести, сталкивается с огромным внутренним спросом, поэтому российский покупатель будет конкурировать за квоты с компаниями, которые в совокупности составляют основу китайской интернет-экономики. В марте 2026 года «Сбер» запустил «ГигаЧат Ультра» с новым режимом рассуждений, а семейство базовых моделей за последний год расширилось за счёт «ГигаЧат 2.0» и «ГигаЧат Макс». Для запуска этих моделей в больших масштабах требуется как оборудование для вывода, так и для обучения, и чипы Ascend 950PR оптимизированы именно для вывода. Чип Huawei 950DT, ориентированный на обучение ИИ-моделей, поступит в продажу не раньше четвёртого квартала 2026 года и будет оснащён 144 Гбайт фирменной памяти Huawei HiZQ 2.0 с пропускной способностью 4 Тбайт/с. Существующая инфраструктура «Сбера» основана на комбинации западных графических процессоров, китайских аналогов и чипов российского производства, которые не обеспечивают конкурентоспособных возможностей для передовых задач ИИ. Если «Сбер» хочет получить полностью китайский вычислительный стек для своего «ГигаЧата», ему понадобятся оба чипа Huawei в огромных объёмах. В январе «Сбер» за 27 млрд ₽ приобрёл 41,9 % акций крупнейшего российского производителя электроники «Элемент». Компания выпускает интегральные схемы и полупроводниковые устройства, на долю которых приходится примерно половина российского производства микроэлектроники, но её продукция ориентирована на оборонные и промышленные приложения, а не на ускорители ИИ для дата-центров. Наиболее передовые российские технологии производства микросхем нацелены на 65-нанометровую литографию к 2030 году, что примерно на 25 лет отстаёт от передовых технологий. В подписанной сегодня совместной декларации лидеров России и Китая содержится призыв к более тесному двустороннему сотрудничеству в области ИИ и информация о создании глобального органа контроля за развитием ИИ. Пока неизвестно, приведёт ли это к фактическим поставкам в Россию китайских ИИ-ускорителей. Baikal обещает к 2030 году выпустить «основу суверенных дата-центров» — отечественные ИИ-чипы, совместимые с Nvidia CUDA
19.05.2026 [09:54],
Павел Котов
Российская Baikal Electronics анонсировала на конференции ЦИПР 2026 в Нижнем Новгороде собственные решения для систем искусственного интеллекта: два ускорителя и серверный комплект с процессорами нового поколения. 
Источник изображений: t.me/anti_agi Старший ускоритель получил название Baikal BE-AI-D1000 — он предназначен для работы на серверах и в центрах обработки данных, выступая в одном классе с представленным в 2023 году NVIDIA L40S. Производительность компонента составляет 1000 Тфлопс (FP8) и 500 Тфлопс (FP16); прочих подробностей в данном аспекте разработчик пока не приводит. Объем памяти составляет от 48 до 64 Гбайт, причём это GDDR, а не высокоскоростная HBM. 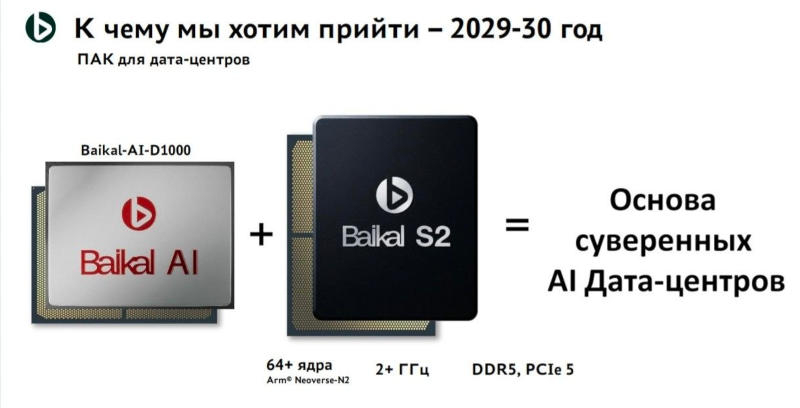 В Baikal не раскрыли, в каком формате исполнен ИИ-ускоритель, неизвестны и механизмы масштабирования — собственный аналог NVLink или открытый UALink. Известно, однако, что стоимость одного ускорителя составит около $10 000. Обещана совместимость с архитектурой CUDA, возможно, через слой трансляции ZLUDA — это позволит штатными средствами запускать PyTorch, TensorFlow и другие популярные фреймворки. Ещё одно нововведение — комплексное серверное решение, сочетающее графический и центральный процессоры. В качестве центрального выступает новый Baikal S2 на архитектуре Arm Neoverse N2, выпущенной в 2020 году. Речь идёт о своего рода отечественном аналоге Nvidia DGX. Разработку ускорителя Baikal ведёт совместно с российскими технологическими гигантами, корректируя проект по обратной связи. Эксперты указывают, что проекты имеют ощутимые перспективы наравне с проектами отечественных базовых станций для операторов мобильной связи. Выпуск продуктов намечен на 2029–2030 гг. AMD выпустила ИИ-ускоритель Instinct MI350P с 144 Гбайт HBM3E, PCIe 5.0 x16 и потреблением 600 Вт
07.05.2026 [21:43],
Николай Хижняк
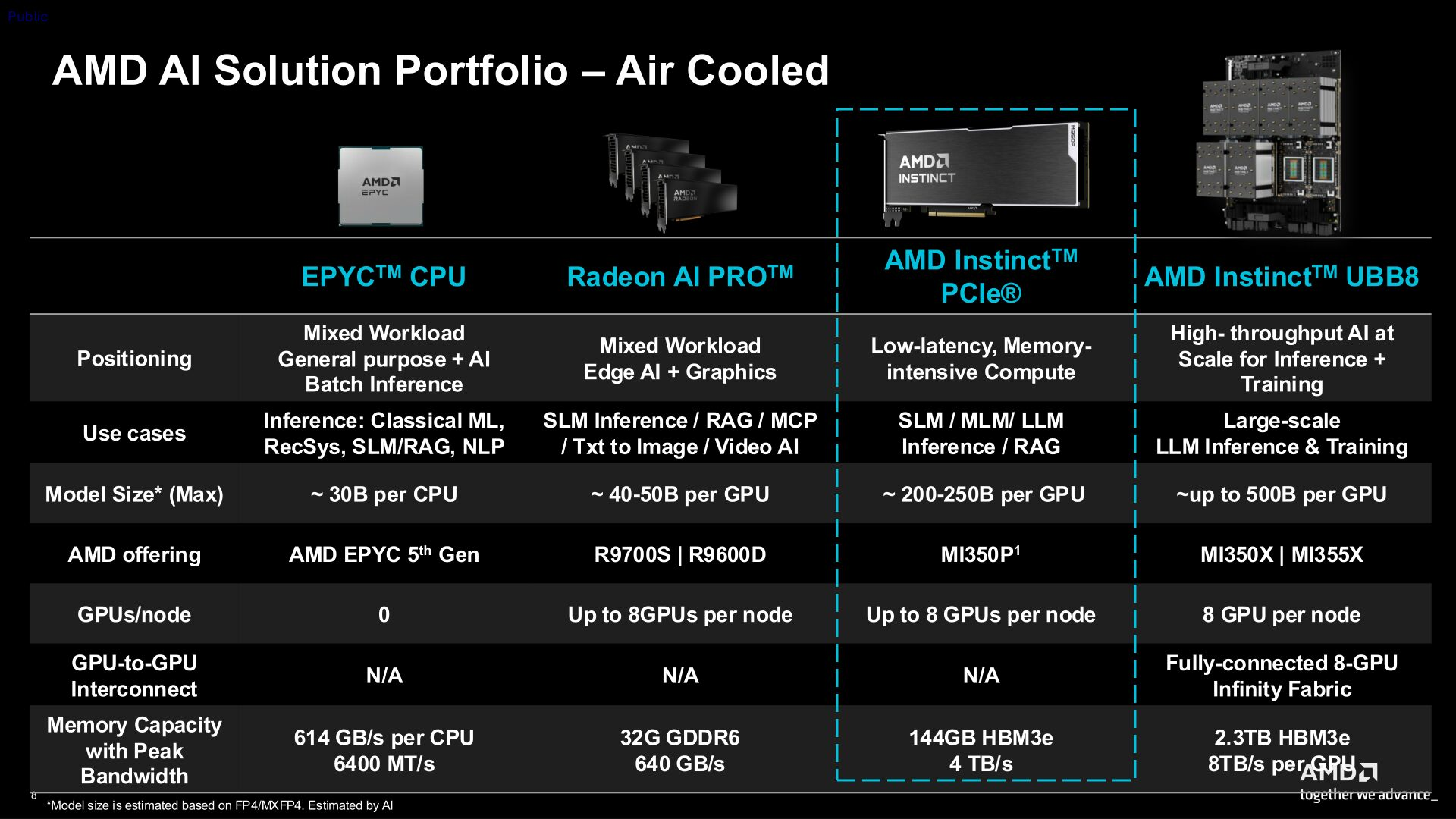
Компания AMD выпустила специализированный графический ускоритель Instinct MI350P в формате карты расширения PCIe. Новинка предназначена для серверов с воздушным охлаждением и ориентирована на развёртывание систем логического вывода для искусственного интеллекта, не требующих полноценной платформы OAM. 
Источник изображений: AMD В составе Instinct MI350P используется графический чип со 128 исполнительными блоками, 8192 потоковыми процессорами и 512 матричными ядрами. AMD заявляет для GPU максимальную частоту 2,2 ГГц. Формально Instinct MI350P представляет собой наполовину урезанную версию Instinct MI350X. 
 Карта получила 144 Гбайт памяти HBM3E с поддержкой 4096-битной шины. Для памяти заявляется пиковая пропускная способность на уровне 4 Тбайт/с. Также ускоритель оснащён 128 Мбайт кеш-памяти последнего уровня и поддерживает функцию ECC (коррекции ошибок) для памяти. Особенности Instinct MI350P
AMD заявляет для Instinct MI350P производительность до 4,6 Пфлопс при работе с матрицами MXFP4 или MXFP6. Карта также обеспечивает производительность 2,3 Пфлопс при работе с матрицами MXFP8 и OCP-FP8, 1,15 Пфлопс — при работе с матрицами FP16 и BF16 и 36 Тфлопс — при работе с матрицами FP64. Благодаря структурированной разреженности некоторые показатели производительности при работе с 8-битными и 16-битными числами удваиваются. 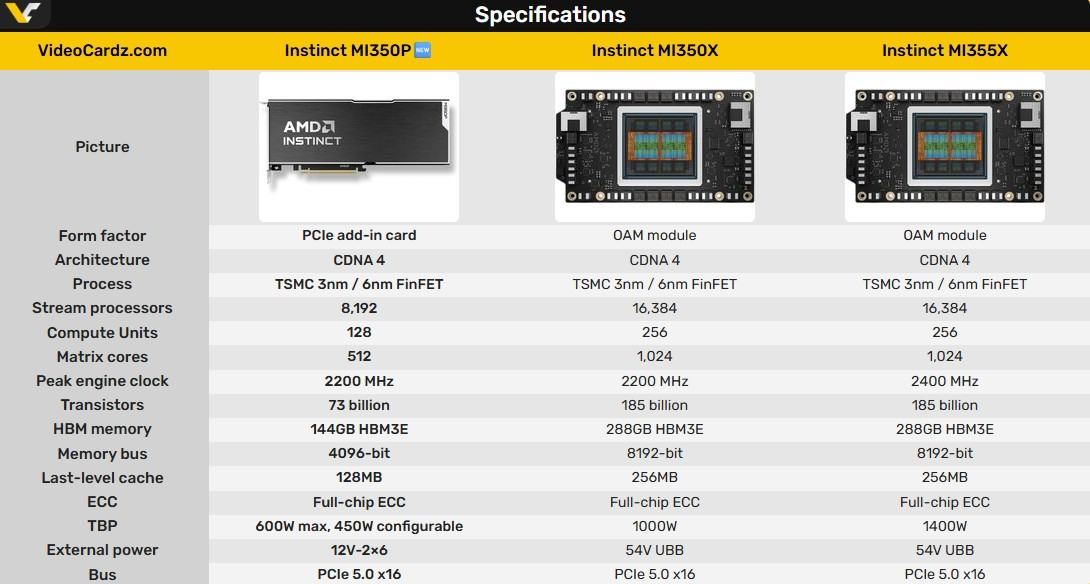 Толщина ускорителя Instinct MI350P составляет два слота расширения, длина карты — 267 мм. Для работы новинка использует интерфейс PCIe 5.0 x16. Подача дополнительного питания на карту обеспечивается через разъём 12V-2×6. Стандартный показатель энергопотребления ускорителя составляет 600 Вт, однако его можно настроить на режим потребления 450 Вт. Цена на серверы с Nvidia B300 на сером рынке Китая взлетела до $1 млн
30.04.2026 [14:21],
Анжелла Марина
На фоне жёстких ограничений на экспорт чипов со стороны США и ажиотажного спроса на вычислительные мощности для искусственного интеллекта цены на серверы Nvidia B300 в Китае выросли почти вдвое, достигнув $1 млн. Критически важные для развития технологий в КНР поставки оборудования, которое идёт через серый рынок, оказались в дефиците из-за ужесточения борьбы с контрабандой. 
Источник изображения: Nvidia По сообщению Reuters, стоимость самого продвинутого сервера Nvidia, оснащённого восемью графическими процессорами B300, в Китае теперь составляет около 7 млн юаней (примерно $1 023 650), тогда как в конце прошлого года показатель находился на отметке в 4 млн юаней (около $584 950). Такой резкий скачок обусловлен давлением на серый рынок, который ранее являлся ключевым каналом поставок, а также устойчивым спросом со стороны местных технологических гигантов. При этом многие китайские компании стараются не указывать оборудование Nvidia в своей отчётности из-за опасений подвергнуться американским санкциям. Сама Nvidia подчеркнула, что B300 запрещён к продаже в Китае, а любые попытки незаконного оборота обречены на провал из-за строгих механизмов контроля. Для сравнения, в США цена аналогичного сервера составляет около 550 тысяч долларов, что также выше прошлогодних показателей. Китайская наценка отражает так называемую надбавку за дефицит, которая возникла после мартовского уголовного преследования американскими властями сооснователя компании Supermicro, являющейся партнёром Nvidia, И Шянь Лио (Yi-Shyan Liaw). Лио обвинили в участии незаконной деятельности по провозу из США в Китай запрещённого серверного оборудования. В результате некоторые компании, не имеющие возможности приобрести серверы в собственность, вынуждены рассматривать варианты аренды, стоимость которой достигает 190 тысяч юаней (примерно $27 800) в месяц по годовому контракту. Однако дефицит оборудования не ослабляет аппетиты местных разработчиков, стремящихся к монетизации своих моделей и вычислительной инфраструктуры. По данным Morgan Stanley, в марте 2026 года доля китайских ИИ-моделей в глобальном потреблении токенов резко возросла, достигнув 32 % по сравнению с 5-% годом ранее. Например, компании MiniMax, Zhipu и Qwen от Alibaba зафиксировали рост использования токенов в шесть-семь раз в феврале и марте по сравнению с декабрём. Для обработки таких массивов данных требуется наиболее эффективное оборудование, каковым является B300 с его 288 Гбайт памяти и вычислительной мощностью 14 петафлопс при точности FP4. К этому добавляется неопределённость вокруг поставок чипов H200, которая также способствует росту цен на B300. Несмотря на получение одобрения от правительств обеих стран, экспорт H200 в Китай так и не начался из-за разногласий по условиям продажи. Напомним, Nvidia и её партнёры начали поставлять B300 ещё в сентябре прошлого года, однако закрытые каналы поставок не позволяют в полной мере удовлетворить запросы китайского рынка и в таких условиях борьба за доступ к мощным вычислительным ресурсам продолжает стимулировать рост цен. Meta✴ купит у AMD чипов на $100 млрд для ИИ-систем на 6 ГВт — и получит «в подарок» кусочек самой AMD
24.02.2026 [19:39],
Сергей Сурабекянц
Компании AMD и Meta✴✴ объявили о ещё одной колоссальной сделке, стоимость которой может превысить $100 млрд. AMD предоставит до 6 гигаватт вычислительной мощности на основе ИИ-ускорителей AMD Instinct для реализации амбиций Meta✴✴ в области ИИ. Сделка предусматривает вознаграждение для Meta✴✴, в рамках которого компания может получить до 160 млн акций AMD. Meta✴✴ также станет ведущим потребителем чипов AMD EPYC Venice и процессоров следующего поколения EPYC Verano. 
Источник изображений: AMD В своём пресс-релизе AMD подтвердила партнёрство с Meta✴✴ с целью «быстрого масштабирования инфраструктуры ИИ и ускорения разработки и внедрения передовых моделей ИИ». С этой целью AMD предоставит Meta✴✴ архитектуру AMD Helios для стоечных систем, начало развёртывания которой ожидается во второй половине 2026 года. Решение будет основано на базе специализированных графических процессоров AMD Instinct, построенных на архитектуре MI450, процессоров AMD EPYC Venice и программного обеспечения ROCm.  Глава AMD Лиза Су (Lisa Su) заявила, что партнёрство с Meta✴✴ представляет собой «многолетнее сотрудничество», а генеральный директор Meta✴✴ Марк Цукерберг (Mark Zuckerberg) подтвердил долгосрочные перспективы партнёрства. По словам Цукерберга, амбиции Meta✴✴ в области искусственного интеллекта направлены на создание «персонального суперинтеллекта». AMD также сообщила, что Meta✴✴ станет ведущим клиентом для процессоров AMD EPYC Venice шестого поколения, а также чипов EPYC следующего поколения Verano. AMD заявила, что выпустила для Meta✴✴ «варранты на основе производительности» на сумму до 160 млн обыкновенных акций AMD, которые будут предоставляться «по мере достижения определённых этапов, связанных с поставками графических процессоров Instinct». По сути, AMD вознаграждает Meta✴✴ своими акциями за покупку графических процессоров. Сделка по масштабу практически идентична партнёрству OpenAI и AMD, объявленному в октябре. По данным The Wall Street Journal, стоимость сделки превышает $100 млрд, при этом каждый гигаватт вычислительных мощностей приносит AMD десятки миллиардов долларов дохода. Что касается сделки с акциями, Meta✴✴ сможет приобрести до 160 млн акций по цене 0,01 доллара за штуку. Для получения полного вознаграждения в виде акций, цена акций AMD должна достичь $600. В настоящее время они торгуется чуть ниже $200. На прошлой неделе сообщалось о намерении Meta✴✴ использовать автономные процессоры Nvidia Grace в своих ЦОД, что, по словам компании, обеспечит значительный скачок производительности на ватт. Топ-менеджер Intel: в половине отгруженных в этом году ПК будет ускоритель ИИ
18.02.2026 [18:12],
Сергей Сурабекянц
Президент японского подразделения Intel Макото Оно (Makoto Ohno) уверен, что 2026 год станет решающим для ПК с поддержкой ИИ. По его прогнозам, в этом году на ПК с ИИ придётся примерно половина от общего объёма поставок за год. По предварительным оценкам IDC, в 2026 году будет отгружено около 260 млн ПК. Если прогноз Макото Оно сбудется, 130 млн из них будут оснащены нейронным процессором (NPU) или другим чипом для локальной обработки данных с помощью ИИ. Тем не менее Макото Оно признал, что основной причиной покупки ПК с ИИ могут оказаться не его возможности по ускорению искусственного интеллекта, а повышенная производительность в широком спектре прикладных задач и более длительное время автономной работы благодаря новым поколениям оптимизированных процессоров. «Прогнозируется, что к 2026 году […] каждый второй компьютер будет ПК с искусственным интеллектом. Однако, учитывая текущую ситуацию, причинами выбора ПК с ИИ являются его высокая производительность и длительное время автономной работы, обеспечиваемое использованием нейронного процессора. Другими словами, важно учитывать тот факт, что люди в настоящее время покупают ПК с ИИ не для того, чтобы использовать его функции, связанные с ИИ», — отметил Макото Оно. По словам Макото Оно, Intel хочет в кратчайшие сроки сделать ПК с ИИ нормой, а не исключением. Компания признает, что в настоящее время эти ПК в основном воспринимаются как продукты высокого класса, и стремится как можно быстрее изменить это восприятие и вывести такие устройства на массовый рынок. Intel также подчеркнула необходимость большего количества приложений, которые действительно используют возможности ПК с ИИ, с целью достижения точки, когда люди будут покупать ПК с ИИ для конкретной цели, а не просто потому, что это новейший продукт. Несмотря на сопротивление Пекина, Nvidia намерена начать поставки чипов H200 в Китай к середине февраля
22.12.2025 [19:34],
Сергей Сурабекянц
Осведомлённые источники сообщают, что Nvidia уведомила китайских клиентов о намерении начать поставки своих вторых по мощности чипов для искусственного интеллекта в Китай до новогодних праздников по китайскому лунному календарю, то есть в середине февраля. Компания планирует выполнить первоначальные заказы из имеющихся запасов. Будет поставлено от 5000 до 10 000 серверов, что эквивалентно 40 000–80 000 чипов H200 для искусственного интеллекта. 
Источник изображений: Nvidia Nvidia также сообщила китайским клиентам о планах наращивания мощностей для производства этих чипов, при этом заказы на эти мощности начнут приниматься во втором квартале 2026 года. Для китайских технологических гигантов, таких как Alibaba Group и ByteDance, которые выразили заинтересованность в покупке чипов H200, потенциальные поставки обеспечат доступ к процессорам, примерно в шесть раз более мощным, чем H20, которые Nvidia разработала специально для Китая. Независимо от озвученных планов Nvidia поставки пока под вопросом, поскольку Пекин ещё не одобрил ни одной закупки H200 и сроки могут измениться в зависимости от решений правительства. Китайские чиновники провели экстренные совещания в начале декабря для обсуждения этого вопроса и пока взвешивают возможность разрешения поставок. Согласно одному из предложений, каждая покупка H200 должна сопровождаться приобретением определённого количества ускорителей ИИ китайского производства. Китай активно развивает собственную индустрию чипов для искусственного интеллекта. Но пока ускорители ИИ от китайских компаний не могут сравниться по производительности с H200, что вызывает у правительства Китая опасения, что разрешение импорта может замедлить внутренний прогресс. Планируемые поставки, если они состоятся, станут первыми поставками ИИ-ускорителей H200 в Китай после того, как администрация США разрешила такие продажи с выплатой 25 % прибыли в американский бюджет. Этот шаг представляет собой серьёзный сдвиг в политике США по сравнению с предыдущей администрацией, которая полностью запретила продажу передовых чипов для ИИ в Китай, ссылаясь на соображения национальной безопасности. Серьёзность намерений правительства США подтверждает начавшаяся на прошлой неделе межведомственная проверка заявок на лицензирование экспорта чипов H200 в Китай.  H200, входящий в линейку Hopper предыдущего поколения от Nvidia, по-прежнему широко используется в ИИ, несмотря на то, что ему на смену пришли ИИ-ускорители поколения Blackwell. Ранее Nvidia сосредоточила усилия на выпуске ускорителей Blackwell и запуске будущей линейки Rubin, что привело к дефициту поставок H200. Google объединилась с Meta✴, чтобы ударить по доминированию Nvidia в сфере ПО для ИИ
18.12.2025 [20:49],
Сергей Сурабекянц
Google работает над улучшением производительности своих ИИ-чипов при работе с PyTorch. Этот проект с открытым исходным кодом является одним из наиболее широко используемых инструментов для разработчиков моделей ИИ. Для ускорения разработки Google сотрудничает с Meta✴✴, создателем и администратором PyTorch. Партнёрство подразумевает доступ Meta✴✴ к большему количеству ИИ-ускорителей. Этот шаг может пошатнуть многолетнее доминирование Nvidia на рынке ИИ-вычислений. 
Источник изображения: unsplash.com Эта инициатива является частью агрессивного плана Google по превращению своих тензорных процессоров (Tensor Processing Unit, TPU) в жизнеспособную альтернативу лидирующим на рынке графическим процессорам Nvidia. Продажи TPU стали важнейшим двигателем роста доходов Google от облачных сервисов. Однако для стимулирования внедрения ИИ-ускорителей Google одного оборудования недостаточно. Новая инициатива компании, известная как TorchTPU, направлена на устранение ключевого барьера, замедляющего внедрение чипов TPU, путём обеспечения их полной совместимости и удобства для разработчиков PyTorch. Google также рассматривает возможность открытия некоторых частей исходного кода своего ПО для ускорения его внедрения. По сравнению с предыдущими попытками поддержки PyTorch на TPU, Google уделяет больше организационного внимания, ресурсов и стратегического значения TorchTPU, поскольку компании, которые хотят использовать эти чипы, рассматривают именно программный стек как узкое место технологии. PyTorch, проект с открытым исходным кодом, активно поддерживаемый Meta✴✴, является одним из наиболее широко используемых инструментов для разработчиков, создающих модели ИИ. В Кремниевой долине очень немногие разработчики пишут каждую строку кода, которую будут фактически выполнять чипы от Nvidia, AMD или Google. Разработчики полагаются на такие инструменты, как PyTorch, представляющий собой набор предварительно написанных библиотек кода и фреймворков. 
Источник изображения: pytorch.org Доминирование Nvidia обеспечивается не только её ускорителями ИИ, но и программной экосистемой CUDA, которая глубоко интегрирована в PyTorch и стала методом по умолчанию для обучения и запуска крупных моделей ИИ. Инженеры Nvidia приложили максимум усилий, чтобы программное обеспечение, разработанное с помощью PyTorch, работало максимально быстро и эффективно на чипах компании. Бо́льшая часть программного обеспечения Google для ИИ построена на основе платформы Jax, что отталкивает клиентов, применяющих для разработки PyTorch. Поэтому сейчас для Google стало особенно важным обеспечить максимальную поддержку PyTorch на своих ускорителях ИИ. В случае успеха TorchTPU может значительно снизить затраты на переход для компаний, желающих найти альтернативу графическим процессорам Nvidia. Чтобы ускорить разработку, Google тесно сотрудничает с Meta✴✴, создателем и администратором PyTorch. Это партнёрство может предоставить Meta✴✴ доступ к большему количеству ИИ-чипов Google. Meta✴✴ прямо заинтересована в разработке TorchTPU — это позволит компании снизить затраты на вывод данных и диверсифицировать инфраструктуру ИИ, отказавшись от использования графических процессоров Nvidia. В качестве первого шага Meta✴✴ предложила использовать управляемые Google сервисы, в рамках которых клиенты, такие как Meta✴✴, получили бы доступ к ИИ-ускорителям Google, а Google обеспечивала их операционную поддержку. В этом году Google уже начала продавать TPU напрямую в центры обработки данных своих клиентов. Компания нуждается в такой инфраструктуре как для запуска собственных продуктов ИИ, включая чат-бот Gemini и поиск на основе ИИ, так и для предоставления доступа клиентам Google Cloud. 
Источник изображения: Google «Мы наблюдаем огромный, ускоряющийся спрос как на нашу инфраструктуру TPU, так и на инфраструктуру GPU, — заявил представитель Google. — Наша цель — обеспечить разработчикам гибкость и масштабируемость, необходимые независимо от выбранного ими оборудования». Как построить 5000-ваттный GPU будущего — Intel расскажет на ISSCC 2026
28.11.2025 [01:39],
Николай Хижняк
Насыщенная программа конференции ISSCC 2026, которая пройдет в феврале будущего года, включает немало интересных тем. Среди них — «как реализовать 5000-ваттные графические процессоры». Идею хочет предложить не абы кто, а заслуженный исследователь Intel, проработавший в компании более 25 лет, пишет Computer Base. 
Источник изображения: Intel Каладхар Радхакришнан (Kaladhar Radhakrishnan) давно и активно работает в области технологий питания микросхем и компонентов. Многочисленные публикации его работ доступны онлайн. На конференции ISSCC в феврале 2026 года он представит один из своих последних проектов, который в полной мере соответствует современным тенденциям: интегрированные решения по регулированию напряжения для графических процессоров мощностью 5 кВт. Презентация состоится 19 февраля в рамках панельной дискуссии, посвященной теме «Обеспечение будущего ИИ, высокопроизводительных вычислений и архитектуры чиплетов: от кристаллов до корпусов и стоек». Ключевая идея предложения — использование в составе GPU интегрированных регуляторов напряжения (IVR). Сама по себе технология IVR не является новинкой в отрасли. Однако её использование в составе графических процессоров для обеспечения значительно более высокой мощности всё ещё остаётся относительно новой областью. Следующее поколение больших GPU в ускорителях ИИ будет потреблять от 2300 до предположительно 2700 Вт. Nvidia Vera Rubin Ultra и её преемник Feynman Ultra, по слухам, будут потреблять более 4000 Вт. Таким образом, цель Intel в 5 кВт для GPU — это совсем не нереалистичная цифра на будущее. Предполагается, что применение IVR в составе GPU потребует использования технологии корпусирования чипов Foveros-B. Данная технология ожидается не ранее 2027 года. Внешних клиентов компания намерена привлекать через своё контрактное производство Foundry. Как пишет Computer Base, компания TSMC также работает над этим направлением со своими партнёрами. GUC, компания, входящая в экосистему TSMC, недавно объявила, что отправила IVR на отладку в составе CoWoS-L. CoWoS-L является самым передовым решением TSMC для корпусирования больших интерпозеров. Технология CoWoS-L ожидается в 2027 году и придёт на смену CoWoS-S, которая сейчас используется для упаковки большинства чипов таких компаний, как Nvidia, AMD и других. В Китае намекнули на создание многочиповых ИИ-ускорителей, способных потягаться с Nvidia Blackwell
27.11.2025 [21:43],
Николай Хижняк
Разработанные в Китае ускорители ИИ из логических чиплетов на основе 14-нм техпроцесса и памяти DRAM на базе 18-нм техпроцесса в состоянии конкурировать с чипами Nvidia Blackwell, которые производятся по 4-нм техпроцессу TSMC. Такое мнение на отраслевом мероприятии озвучил Вэй Шаоцзюнь (Wei Shaojun), заместитель председателя Китайской ассоциации полупроводниковой промышленности и профессор Университета Цинхуа, сообщает DigiTimes. 
Источник изображения: AMD Выступая на глобальном саммите руководителей высшего звена ICC, Вэй Шаоцзюнь отметил, что ключом к прорыву в области производительности и эффективности станет передовая технология 3D-стекинга, используемая при создании китайских ускорителей. Вэй Шаоцзюнь, ранее заявивший, что цели, поставленные Китаем в рамках программы «Сделано в Китае 2025», недостижимы, и позднее призвавший страну отказаться от использования иностранных ускорителей искусственного интеллекта, таких как Nvidia H20, и перейти на отечественные решения, описал гипотетическое «полностью контролируемое отечественное решение», которое объединит 14-нм логику с 18-нм DRAM с использованием 3D-гибридной склейки. Никаких доказательств разработки или хотя бы подтверждений возможности реализации подобного решения с использованием имеющихся у Китая технологий при этом он не привёл. По словам Вэя, такая конфигурация призвана приблизиться к производительности 4-нм графических процессоров Nvidia, несмотря на использование устаревших технологий. Он считает, что такое решение может обеспечить производительность 120 терафлопс. Он также заявил, что энергопотребление составит всего около 60 Вт, что, по словам Вэя, обеспечит более высокую производительность (2 терафлопса на ватт) по сравнению с процессорами Intel Xeon. Для сравнения: ускоритель Nvidia B200 обеспечивает производительность 10 000 NVFP4-терафлопс при потреблении 1200 Вт, что составляет 8,33 NVFP4-терафлопса на ватт. Nvidia B300 обеспечивает производительность 10,7 NVFP4-терафлопса на ватт, что в пять раз превышает возможности ИИ-ускорителя, о котором заявил Вэй. Ключевыми технологиями, призванными значительно повысить производительность ИИ-ускорителя, разрабатываемого в Китае, являются 3D-гибридное соединение (медь-медь и оксидное соединение), которое заменяет столбиковые выводы припоя прямыми медными соединениями с шагом менее 10 мкм, а также вычисления, близкие к уровню оперативной памяти. Гибридное склеивание с шагом менее 10 мкм позволяет создавать от десятков до сотен тысяч вертикальных соединений на 1 мм², а также сигнальные тракты микрометрового масштаба для высокоскоростных соединений с малой задержкой. Одним из лучших примеров технологии гибридного 3D-склеивания является 3D V-Cache от AMD, обеспечивающий пропускную способность 2,5 Тбайт/с при энергии ввода-вывода 0,05 пДж/бит. Вэй, вероятно, рассчитывает на аналогичный показатель для своего проекта. 2,5 Тбайт/с на устройство — это значительно выше, чем пропускная способность памяти HBM3E, поэтому это может стать прорывом для ускорителей ИИ, основанных на концепции вычислений, близких к оперативной памяти. Вэй также отметил, что теоретически эта концепция может масштабироваться до производительности уровня зеттафлопс, хотя он не уточнил, когда и как такие показатели будут достигнуты. Вэй обозначил платформу CUDA от Nvidia как ключевой риск не только для описанной им альтернативы, но и для аппаратных платформ, отличных от Nvidia, поскольку после объединения программного обеспечения, моделей и аппаратного обеспечения на единой проприетарной платформе становится сложно развернуть альтернативные процессоры. Учитывая, что он рассматривал вычисления, близкие к уровню оперативной памяти, как способ значительного повышения конкурентоспособности оборудования для ИИ, разработанного в Китае, любая альтернативная платформа, не основанная на этой концепции (включая китайские ускорители ИИ, например серию Huawei Ascend или графические процессоры Biren), может считаться несовместимой. Маск пообещал дешёвые ИИ-серверы в космосе через пять лет — Хуанг назвал эти планы «мечтой»
21.11.2025 [18:29],
Сергей Сурабекянц
Помимо стоимости оборудования, требования к электроснабжению и отведению тепла станут одними из основных ограничений для крупных ЦОД в ближайшие годы. Глава X, xAI, SpaceX и Tesla Илон Маск (Elon Musk) уверен, что вывод крупномасштабных систем ИИ на орбиту может стать гораздо более экономичным, чем реализация аналогичных ЦОД на Земле из-за доступной солнечной энергии и относительно простого охлаждения. 
Источник изображений: AST SpaceMobile «По моим оценкам, стоимость электроэнергии и экономическая эффективность ИИ и космических технологий будут значительно выше, чем у наземного ИИ, задолго до того, как будут исчерпаны потенциальные источники энергии на Земле, — заявил Маск на американо-саудовском инвестиционном форуме. — Думаю, даже через четыре-пять лет самым дешёвым способом проведения вычислений в области ИИ будут спутники с питанием от солнечных батарей. Я бы сказал, не раньше, чем через пять лет». Маск подчеркнул, что по мере роста вычислительных кластеров совокупные требования к электроснабжению и охлаждению возрастают до такой степени, что наземная инфраструктура с трудом справляется с ними. Он утверждает, что достижение непрерывной выработки в диапазоне 200–300 ГВт в год потребует строительства огромных и дорогостоящих электростанций, поскольку типичная атомная электростанция вырабатывает около 1 ГВт. Между тем, США сегодня вырабатывают около 490 ГВт, поэтому использование львиной её доли для нужд ИИ невозможно. Маск считает, что достижение тераваттного уровня мощности для питания наземных ЦОД нереально, зато космос представляет заманчивую альтернативу. По мнению Маска, благодаря постоянному солнечному излучению, аккумулирование энергии не требуется, солнечные панели не требуют защитного стекла или прочного каркаса, а охлаждение происходит за счёт излучения тепла. Глава Nvidia Дженсен Хуанг (Jensen Huang) признал, что масса непосредственно вычислительного и коммуникационного оборудования внутри современных стоек Nvidia GB300 исчезающе мала по сравнению с их общей массой, поскольку почти вся конструкция — примерно 1,95 из 2 тонн — по сути, представляет собой систему охлаждения. Но, кроме веса оборудования, существуют и другие препятствия. Теоретически космос — хорошее место как для выработки энергии, так и для охлаждения электроники, поскольку в тени температура может опускаться до -270 °C. Но под прямыми солнечными лучами она может достигать +125 °C. На околоземных орбитах перепады температур не столь экстремальны:
Низкая и средняя околоземные орбиты не подходят для космических ЦОД из-за нестабильной освещённости, значительных перепадов температур, пересечения радиационных поясов и регулярных затмений. Геостационарная орбита лучше подходит для этой цели, но и там эксплуатация мощных вычислительных кластеров столкнётся с множеством проблем, главная из которых — охлаждение. В космосе отвод тепла возможен только при помощи излучения, что потребует монтажа огромных радиаторов площадью в десятки тысяч квадратных метров на систему мощностью несколько гигаватт. Вывод на геостационарную орбиту такого количества оборудования потребует тысяч запусков тяжёлых ракет класса Starship.  Не менее важно, что ИИ-ускорители и сопутствующее оборудование в существующем виде не способны выдержать воздействие радиации на геостационарной орбите без мощной защиты или полной модернизации конструкции. Кроме того, высокоскоростное соединение с Землёй, автономное обслуживание, предотвращение столкновения с мусором и обслуживание робототехники пока находится в зачаточном состоянии, учитывая масштаб предлагаемых проектов. Так что скорее всего Хуанг прав, когда называет затею Маска «мечтой». Мечтает о выводе масштабных вычислительных кластеров не только Маск. В октябре основатель Amazon и Blue Origin Джефф Безос (Jeff Bezos) в ходе мероприятия Italian Tech Week в Турине (Италия) поделился своим видением развития индустрии космических дата-центров. По его мнению, такие объекты обеспечат ряд значительных преимуществ по сравнению с наземными ЦОД. В сентябре компания Axiom Space с партнёрами сообщила о создании первого орбитального дата-центра, который разместился на МКС. Этот ЦОД будет обслуживать не только станцию, но также любые спутники с оптическими терминалами на борту. В мае Китай вывел на орбиту Земли 12 спутников будущей космической группировки Star-Compute Program, которая в перспективе будет состоять из 2800 спутников. Все они оснащены системами лазерной связи и несут мощные вычислительные платформы — по сути, это первый масштабный ЦОД с ИИ в космосе. Компания Crusoe намерена развернуть свою облачную платформу на спутнике Starcloud запуск которого запланирован на конец 2026 года. Ограниченный доступ к ИИ-мощностям в космосе должен появиться к началу 2027 года Google рассказала об инициативе Project Suncatcher, предусматривающей использование группировок спутников-ЦОД на основе фирменных ИИ-ускорителей. Спутники будут связаны оптическими каналами. Илон Маск хочет на порядок больше ИИ-чипов, чем выпускает вся полупроводниковая индустрия мира
18.11.2025 [18:36],
Сергей Сурабекянц
Амбиции Илона Маска (Elon Musk) в области искусственного интеллекта настолько велики, что он хочет получить больше ускорителей ИИ, чем отрасль в настоящее время может произвести. По его словам, Tesla нуждается в «100–200 миллиардах чипов с искусственным интеллектом в год», и если она не сможет получить их от производителей, то рассмотрит возможность создания собственных фабрик. 
Источник изображения: dogegov.com Маск заявил, что «испытывает огромное уважение к TSMC и Samsung», но он считает, что эти компании не в состоянии удовлетворить потребность его предприятий в чипах ИИ: «Когда я спросил, сколько времени займёт строительство новой фабрики по производству чипов, они ответили, что до запуска производства им потребуется пять лет. Пять лет для меня — это вечность. Мои сроки — год, два. […] Если они передумают и […] будут поставлять нам 100–200 миллиардов ИИ-чипов в год в те сроки, когда они нам нужны, это будет здорово». Маск не уточнил, когда Tesla и SpaceX потребуются эти 100–200 миллиардов ИИ-процессоров в год, но в любом случае выпуск такого количества чипов практически неосуществим, если он имел в виду единицы, а не сумму в долларах. По данным Ассоциации полупроводниковой промышленности, в 2023 году по всему миру произведено 1,5 трлн чипов. Однако в это число входят любые микросхемы — от крошечных микроконтроллеров и датчиков до чипов памяти и ускорителей ИИ. 
Источник изображений: Tesla Такие ускорители ИИ, как Nvidia H100 или B200/B300, представляют собой огромные кремниевые блоки, которые сложно и дорого производить, поэтому на их изготовление уходит больше всего времени. По словам Маска, энергопотребление его ИИ-процессоров AI5 составит 250 Вт, в то время как графические процессоры Nvidia B200 могут потреблять до 1200 Вт. Этот параметр может служит косвенной оценкой размера чипов. Даже если чип AI5 будет в пять раз меньше Nvidia B200, мощностей для достижения целей Маска всё равно совершенно недостаточно. Будучи одним из крупнейших клиентов TSMC, Nvidia поставила четыре миллиона графических процессоров Hopper стоимостью $100 млрд (не считая Китая) за весь срок службы архитектуры, который составил около двух календарных лет. С Blackwell Nvidia продала около шести миллионов графических процессоров за первые четыре квартала их жизненного цикла. Если Маск действительно имел в виду 200 миллиардов устройств, то он хотел бы получить на порядки больше процессоров для искусственного интеллекта, чем отрасль (бо́льшая часть которой приходится на TSMC) может производить за год. Если он всё же подразумевал потребность в ИИ-чипах на сумму от $100 до $200 млрд, то TSMC и Samsung, безусловно, смогут поставить такой объём в ближайшие годы. Однако, похоже, что он действительно считает, что ему нужно больше, чем эти компании могут предложить.  «Мы будем использовать фабрики TSMC на Тайване и в Аризоне, фабрики Samsung в Корее и Техасе, — сказал Маск. — С их точки зрения, они движутся молниеносно. […] тем не менее, это будет для нас ограничивающим фактором. Они работают на пределе своих возможностей, но с их точки зрения — это “педаль в пол”. У них просто не было компании, которая разделяла бы наше понимание срочности. Возможно, единственный способ масштабироваться с желаемой скоростью — это построить действительно большой завод или быть ограниченным в производстве Optimus и беспилотных автомобилей из-за [поставок] ИИ-чипов. Действительно ли потребность Tesla и SpaceX в ИИ-чипах настолько высока, остаётся неясным. Tesla продала 1,79 млн автомобилей в 2024 году, поэтому ей вряд ли требуется больше двух миллионов чипов для своих автомобилей. Конечно, компаниям Маска могут понадобиться ещё миллионы ИИ-процессоров для обучения ИИ, но маловероятно, что Маск в ближайшее время готов создать ИИ-кластеры на базе миллиардов чипов. Антропоморфные роботы Optimus также вряд ли потребуют таких объёмов чипов в ближайшие годы.  Ранее мы писали, как воодушевлённый итогами голосования по новому компенсационному плану Илон Маск на собрании акционеров фонтанировал обещаниями и идеями, и по традиции пританцовывал в момент появления на сцене человекоподобного робота Optimus. Тогда он заявил, что для достижения поставленных новым планом целей Tesla вынуждена будет наладить самостоятельный выпуск чипов. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex