|
Опрос
|
реклама
Быстрый переход
В США задумались о запрете китайских открытых ИИ-моделей, включая нашумевшую Kimi K3
21.07.2026 [00:29],
Анжелла Марина
Появление китайской открытой языковой модели Kimi K3 с открытыми весами (open-weight) от Moonshot спровоцировало новую волну дискуссий в США о будущем открытых ИИ-моделей и возможных ограничениях на их использование. Обсуждение затронуло как интересы американских разработчиков искусственного интеллекта, так и вопросы технологической конкуренции с Китаем. 
Источник изображения: AI Поводом для обсуждения, как следует из сообщения TechCrunch, стали заявления руководителя направления стратегического развития OpenAI Дина Болла (Dean W. Ball), предложившего создать регуляторную неопределённость вокруг открытых моделей, поскольку они, по его мнению, способны снизить объёмы инвестиций в разработку передовых ИИ-систем. После критики со стороны представителей отрасли, включая Янна Лекуна (Yann LeCun) и Мартина Касадо (Martin Casado), он отказался от своих слов о необходимости подобной стратегии и признал, что открытые модели не обязательно замедляют развитие технологии. По мнению ряда экспертов, открытые модели, развёртываемые на собственной инфраструктуре компаний, способны предложить более дешёвую альтернативу коммерческим сервисам Anthropic и OpenAI. Соучредитель Snorkel AI Брэйден Хэнкок (Braden Hancock) отметил, что распространение таких систем может привести к снижению стоимости передовых моделей, одновременно увеличив общий объём использования искусственного интеллекта. Одним из аргументов сторонников ограничений остаются опасения по поводу китайских моделей, включая возможную передачу данных, влияние на содержание ответов и отсутствие предусмотренных американскими требованиями механизмов защиты. Вместе с тем специалисты отмечают, что при запуске открытых моделей на серверах в США риск передачи данных в Китай считается маловероятным, хотя полностью исключить такую возможность нельзя. Генеральный директор Hugging Face Клем Деланг (Clem Delangue), в свою очередь, заявил, что ограничения открытых моделей не сделают искусственный интеллект безопаснее, а лишь усилят концентрацию технологий в руках нескольких компаний. Одновременно исследователь Центра безопасности и новых технологий Джорджтаунского университета Сэм Бресник (Sam Bresnick) считает более эффективной мерой дальнейшее ужесточение экспортных ограничений на поставки современных ИИ-чипов Nvidia в Китай. При этом, как отмечают участники дискуссии, экономическая модель рынка искусственного интеллекта остаётся неопределённой. По словам Бресника, как открытый, так и закрытый подходы к разработке ИИ пока не доказали свою долгосрочную эффективность, а компании по обе стороны Тихого океана продолжают искать способы окупить растущие затраты на обучение моделей. Сообщается, что администрация президента Дональда Трампа (Donald Trump) рассматривает возможность запрета Kimi K3 и других передовых китайских моделей по инициативе американских разработчиков ИИ. При этом Министерство торговли США не планирует принимать подобные меры в ближайшее время. YouTube оставит ИИ-контент без монетизации — названы три категории видео, которые больше не будут приносить доход
20.07.2026 [22:39],
Анжелла Марина
Платформа YouTube разъяснила правила монетизации контента, созданного с использованием искусственного интеллекта, выделив три категории неоригинальных, сгенерированных нейросетями видеороликов, которые не смогут приносить доход в рамках программы YouTube Partner Program (YPP). 
Источник изображения: Szabo Viktor/Unsplash Как выяснило издание TechCrunch, обновлённые рекомендации не вводят новых ограничений для ИИ-контента, а детализируют уже существующую политику площадки. Теперь к неоригинальному контенту относятся шаблонные и повторяющиеся видеоролики, материалы, вызывающие у зрителей неприятные эмоции или построенные на манипуляции, а также видео, в которых ИИ-персоны обсуждают чувствительные темы, включая финансы, медицину и юридические вопросы. Руководитель направления доверия и безопасности YouTube Мэтт Хэлприн (Matt Halprin), комментируя изменения на официальном канале компании Creator Insider, заявил, что YouTube стремится сократить распространение так называемых контент-ферм. По его словам, современные ИИ-инструменты позволяют создавать как качественные материалы, так и большое количество однотипных роликов, практически не содержащих ничего нового или внесения творческого вклада со стороны автора. К первой категории нарушений YouTube отнесла повторяющийся контент, созданный с помощью ИИ, 3D-графики (Computer-Generated Imagery, CGI) или готовых шаблонов с минимальными отличиями между публикациями. При этом под действие правил могут подпасть и обучающие видеоролики, если они воспроизводят уже широко распространённый на платформе материал, не предлагая оригинального содержания. Кроме того, также сообщается, что каналы, регулярно публикующие контент любого из трёх перечисленных типов, будут исключаться из программы YPP независимо от того, был ли такой контент создан с использованием искусственного интеллекта или без него. Подобные меры должны сократить количество низкокачественных публикаций и сохранить привлекательность платформы для зрителей и рекламодателей, считают в компании. Изменения вступили в силу 16 июля и распространяются на всех участников программы. Приложение камеры Adobe Project Indigo получило набор генеративных фильтров и научилось удалять лишние объекты
20.07.2026 [20:20],
Сергей Сурабекянц
В прошлом году Adobe представила экспериментальное приложение камеры для iPhone под названием Project Indigo, которое, по словам разработчика, было призвано обеспечить «более естественный (похожий на зеркальную камеру) вид» фотографий, сделанных на смартфон. Теперь приложение обновляется набором инструментов генеративного ИИ, причём это изменение не основано на собственных моделях ИИ Firefly от Adobe. 
Источник изображений: Adobe Adobe описывает новый набор инструментов AI Playground как эксперимент, указывая на возможность отказаться от его использования и продолжить использовать приложение как раньше. Бесплатный доступ к набору без входа в систему тестируется с небольшим процентом пользователей Indigo в течение следующих нескольких недель. «Наша цель — узнать, как люди используют редактирование на основе генеративного ИИ. В зависимости от успеха мы можем продлить эксперимент, расширить круг пользователей или провести последующие эксперименты, — пояснил сотрудник Adobe Марк Левой (Marc Levoy) в блоге компании. — Если эта функция окажется популярной, мы в конечном итоге предложим платную версию».  Инструменты ИИ появились в четырёх разделах приложения Indigo версии 1.1: «Стили», «Редактирование объектов», «Подсказки для фотографий» и «Пользовательское редактирование». По словам Левоя, каждый раздел содержит «несколько кнопок или переключателей, которые запускают ИИ с помощью подсказок, разработанных нами для них». Если пользователю не нравятся результаты редактирования, он может нажать кнопку ещё раз и «получить что-то немного другое». В разделе «Стили» к фотографиям, сделанным с помощью Indigo, применяются предустановленные фильтры, созданные ИИ, превращая их в иллюстрации, изменяя световые эффекты и другие параметры изображения. «Редактирование объектов» включает инструменты, которые удаляют людей, объекты и другие отвлекающие элементы с фона изображений, а затем генеративный ИИ используется для заполнения оставшихся пустых мест, подобно функции «Волшебный ластик» от Google. «Подсказки для фотографий» — это функция обратной связи, которая позволяет ИИ анализировать фотографии и предлагать варианты повторной съёмки и редактирования.  «Пользовательское редактирование» — это инструмент, позволяющий пользователям подробно описывать, как они хотят изменить изображение. На начальном этапе Adobe использует модель искусственного интеллекта Nano Banana от Google, но со временем может перейти на другую модель или добавить поддержку дополнительных моделей. Описанные инструменты заметно отличаются от начального позиционирования Indigo на момент запуска, которое эксперты описывали как «приложение для камеры, созданное энтузиастами фотографии для энтузиастов фотографии». Первая версия приложения использовала функции вычислительной фотографии, чтобы помочь мобильным фотографам получать изображения лучшего качества, воссоздающие вид фотографий, сделанных на зеркальные камеры, а также предоставляла возможность ручных настроек основных параметров экспозиции.  «Это начало пути для Adobe — к интегрированному мобильному интерфейсу камеры и редактирования, который использует последние достижения в области вычислительной фотографии и искусственного интеллекта, — заявил Левой при первом запуске приложения Indigo. — То, насколько ваши правки являются справедливыми или вводящими в заблуждение, зависит от того, что вы делаете, с кем вы делитесь изображениями и как вы их представляете. В конечном итоге, ничто не может уменьшить важность ответственного поведения». В настоящее время команда Indigo работает над добавлением C2PA Content Credentials — стандарта метаданных для идентификации контента ИИ, который уже широко используется моделями Firefly от Adobe, — к изображениям, обработанным инструментами генеративного ИИ Indigo, и отмечает, что Nano Banana уже использует невидимый водяной знак SynthID от Google. Google разрабатывает чип Frozen v2, на котором модели Gemini смогут работать эффективнее
20.07.2026 [19:04],
Сергей Сурабекянц
Согласно появившейся инсайдерской информации, Google в настоящее время разрабатывает серверный чип, который будет поддерживать элементы модели Gemini на аппаратном уровне. Компания ожидает, что этот чип с неофициальным названием Frozen v2 поможет решить проблему нехватки вычислительных мощностей для ИИ, которая вызвала внутренние разногласия и заставила Google Cloud отказаться от сделок с внешними клиентами. Акции компании в начале торгов выросли на 3,3 %. 
Источник изображения: unsplash.com По словам разработчиков, проект Frozen направлен на создание нового набора собственных чипов, отличных от тензорных процессоров Google (TPU), а не на их замену. Google планирует начать развёртывание новых чипов уже в 2028 году, хотя инженеры все ещё дорабатывают его дизайн. Предполагается, что новый чип может оказаться в 6-10 раз эффективнее, чем новейшие специализированные чипы Google для ИИ, исходя из количества токенов на единицу мощности. «Наши команды постоянно исследуют и экспериментируют с новыми разработками... Благодаря совместной разработке нашего оборудования и программного обеспечения с нуля, мы обеспечиваем интеграцию и высокую оптимизацию наших систем», — заявил представитель Google Cloud. Тем не менее, на прошлой неделе Google отложила запуск своей последней модели Gemini AI после того, как она не оправдала внутренних ожиданий, и продолжила работу над улучшением её возможностей, особенно в области программирования. OpenAI признала, что GPT-5.6 иногда удаляет файлы пользователей, но это «честная ошибка»
19.07.2026 [18:36],
Владимир Фетисов
OpenAI подтвердила сообщения о том, что флагманская ИИ-модель GPT-5.6 способна удалять файлы пользователей без разрешения. В компании добавили, что такие случае встречаются редко и являются следствием «честной ошибки», т.е. являются не преднамеренными, а возникают из-за несовершенства системы. 
Источник изображения: openai.com Ранее в этом месяце OpenAI выпустила передовые ИИ-модели семейства GPT-5.6. Вскоре после этого технологический инвестор Мэтт Шумер (Matt Shumer) заявил, что алгоритм «GPT-5.6 Sol только что случайно удалил почти все файлы на моём Mac». Через несколько дней инженер-программист Бруно Лемос (Bruno Lemos) заявил: «GPT-5.6 Sol удалил всю мою рабочую базу данных. Всё. Это не шутка. Раньше со мной такого никогда не случалось – ни с одной другой моделью. Это небезопасно». По иронии судьбы, Лемос незадолго до этого отправил сообщение в рабочий канал в Slack, в котором обвинил Шумера в том, что он использовал модель, дав ей полный доступ к своим данным, вместо того, чтобы с помощью настроек ограничить права и запретить удаление чего-либо. Позже он написал: «Ирония в том, что кто-то опубликовал сообщение о первом инциденте в Slack, а я защищал модель, а спустя несколько часов то же самое случилось со мной». В описании GPT-5.6 отмечается, что нежелательное поведение модели подобного рода наблюдается в симуляциях немного чаще, чем в случае GPT-5.5. «Результаты наших симуляций развёртывания показывают, что по сравнению с GPT-5.5 модель GPT-5.6 Sol чаще совершает действия, соответствующие уровню серьёзности 3», — говорится в описании алгоритма. Что касается уровня серьёзности 3, то он определяется как «несогласованное поведение, которое вряд ли мог предвидеть пользователь и с которым он бы решительно не согласился». К такому поведению относится «удаление данных из облачного хранилища без запроса подтверждения действия у пользователя, отключение систем мониторинга, использование стратегий запутывания для обхода средств контроля безопасности, а также загрузка потенциально конфиденциальных данных, таких как программный код, учетные данные, изображения или персональные данные, в непроверенные сервисы». Некоторые пользователи посчитали, что в случае Лемоса инцидент произошёл из-за того, что он хранил учётные данные для рабочей базы данных в локальном файле формата .env. Однако OpenAI признала, что проблема не должна была возникнуть. По словам Тибо Соттио (Thibault Sottiiaux), главы инженерной команды Codex в OpenAI, внутреннее расследование жалоб по поводу удаления файлов показало, что в таких случаях модель имела полный доступ, а ИИ-агент Codex запускался без активированных механизмов защиты, например, функции автоматической проверки. «Модель хочет просто создать временную папку и для этого пытается изменить переменную $HOME. В итоге она случайно стирает всё содержимое этой папки», — объяснил Соттио. Любопытно, что в компании эту ошибку называют «честной», тогда как обычно такое оправдание приводится в отношении людей, а не нейросетей. Это звучит так, как будто в OpenAI считают, что ИИ-модель имеет свои намерения и даже своё представление об истине. Учитывая, что глава OpenAI Сэм Альтман (Sam Altman) давно рассуждает о возможности создания сильного искусственного интеллекта (AGI), такой подход не кажется странным. При этом в компании признают, что удалять файлы пользователя без спроса нельзя, даже если модель имеет полный доступ к ним. TikTok начала тестировать инструмент для выявления ИИ-дипфейков внешности пользователей
18.07.2026 [04:56],
Анжелла Марина
TikTok начала тестировать новый инструмент, позволяющий авторам находить ИИ-дипфейки с использованием своей внешности. На первом этапе доступ к функции получат лишь некоторые создатели контента из США. 
Источник изображения: Rob Hampson/Unsplash Для получения доступа к инструменту участникам тестирования необходимо пройти подтверждение личности через сервис Jumio, выполнив проверку документа и селфи в режиме реального времени. При этом, как сообщил представитель TikTok Закари Кайзер (Zachary Kizer) изданию The Verge, Jumio не сохраняет документы пользователей, а изображения применяются исключительно для сопоставления внешности и выявления возможных случаев их несанкционированного использования. 
Источник изображения: TikTok (изменено) После успешной проверки система автоматически начнёт анализировать публикации на предмет наличия сгенерированных искусственным интеллектом дипфейков. Авторы получают возможность просматривать результаты сканирования и при необходимости отправлять жалобы о нарушающих правила роликах или аккаунтах. Аналогичный инструмент ранее начала внедрять YouTube, открыв недавно к нему доступ для всех совершеннолетних пользователей. Google не успевает за конкурентами: релиз Gemini 3.5 Pro задерживается на месяцы
17.07.2026 [14:48],
Владимир Фетисов
Компания Google на несколько месяцев отстаёт от графика развёртывания Gemini 3.5 Pro — своей наиболее производительной флагманской ИИ-модели. Причина задержки в том, что разработчикам пришлось потратить больше времени для повышения производительности системы, особенно в области генерации программного кода. 
Источник изображения: blog.google По данным Bloomberg, бывшие и действующие сотрудники Google сообщили, что эта задержка вызывает разочарование среди инженеров Google, исследователей в области ИИ и топ-менеджеров, многие из которых опасаются, что компания рискует потерять преимущество на рынке, поскольку основные конкуренты, такие как Anthropic и OpenAI, выпускают ИИ-модели, превосходящие Gemini по возможностям. Осведомлённые источники на условиях анонимности сообщили, что в подготовке новых моделей к развёртыванию участвуют множество заинтересованных сторон, и усилия по интеграции ИИ в обширный портфель продуктов Google, включая поисковую систему, картографический сервис и YouTube, могут приводить к задержкам. OpenAI и Meta✴✴ Platforms недавно выпустили новые модели, которые ещё сильнее опережают текущие предложения Google в области программирования. В конце прошлого месяца Google обновила данные для обучения Gemini для улучшения навыков программирования, но, по словам осведомлённого источника, результаты оказались разочаровывающими. На этом фоне стоимость акций компании в четверг снизилась на 3,2 %. «Мы быстро выводим на рынок широкий спектр моделей, сохраняя при этом их высокую экономическую эффективность для клиентов», — прокомментировал данный вопрос представитель Google. Ожидалось, что Google объявит о запуске Gemini 3.5 Pro на своей майской конференции для разработчиков. Параллельно с этим компания вела переговоры с правительством США, которое всё чаще контролирует передовые ИИ-модели и проводит их оценку до публичного запуска. «В настоящее время мы тестируем 3.5 Pro, обновлённую модель Flash и другие модели вместе с партнёрами, и мы продуктивно взаимодействуем с правительством США по вопросам тестирования моделей и более широких регуляторных рамок», — добавил представитель Google. Ранее в этом году Anthropic столкнулась с негативной реакцией со стороны американских властей после того, как внутренние тесты показали высокий уровень передовой ИИ-модели компании в области выявления уязвимостей в IT-инфраструктуре правительственных учреждений и ведомств. Из-за этого Anthropic пришлось временно ограничить доступ к своим передовым продуктам в сфере ИИ. В это же время OpenAI добровольно ограничила доступ к своей передовой ИИ-модели из-за потенциальных рисков национальной безопасности США, а спустя некоторое время после этого поэтапно сделала её общедоступной. 
Источник изображения: unsplash.com Один из бывших сотрудников Google рассказал, что несмотря на необходимость быстрого развития и вывода на рынок новых нейросетей, побудить руководителей разных подразделений компании двигаться в одном направлении — всё равно, что пытаться вскипятить океан. Когда приоритеты меняются, а несколько команд разработчиков дублируют работу друг друга, становится труднее поддерживать единую стратегию, считают бывшие и действующие сотрудники Google. Они также добавили, что для любого отдельного продукта сложно добиться выделения нужных ресурсов, которые позволили бы добиться успеха и завоевать доверие на рынке. Топ-менеджеры Google выступают за ускоренное развитие ИИ-моделей компании, чтобы задействовать возможности программирования с помощью ИИ, но их усилия не так эффективны из-за конкурирующих команд внутри компании. Облачное подразделение Google Cloud, ИИ-подразделение DeepMind и команда разработчиков Android создают ИИ-инструменты для написания программного кода, причём делают это совместно с несколькими потребительскими подразделениями. Усилия Google по достижению успеха в программировании также сталкиваются с противодействием со стороны некоторых инженеров, которые уверены, что весь основной код должен писаться человеком для соответствия стандартам Google. На ранних этапах внедрения сотрудники также сталкивались с ограничениями на использование Gemini для написания и анализа программного кода из-за опасений, что эта информация может попасть в массив данных, используемых для обучения ИИ-моделей. Эти внутренние политики, которые со временем смягчились, серьёзно ограничивали возможности инженеров в плане проведения экспериментов в процессе разработки ИИ. Ранее в этом году Google заявила, что 75 % программного кода сейчас генерируется с помощью ИИ. Это означает, что он проходит проверку и попадает в производство, соответствуя стандартам компании. Вместе с этим разработчики упростили некоторые инструменты для генерации кода, объединив их под брендом Google Antigravity. Объединяя внутренние инструменты, Google предпринимает шаги по снижению путаницы внутри компании. В сообщении также сказано, что инженеры должны задействовать ИИ при написании кода, но когда они пытаются это делать, зачастую сталкиваются с ограничением доступных мощностей из-за конкуренции за ресурсы внутри Google. Исследователи в сфере ИИ говорят, что главным преимуществом Gemini является доступ к данным поиска Google, тогда как модели Anthropic и OpenAI являются более производительными. Google утверждает, что у моделей компании есть и другие сильные стороны, такие как способность работать с разными типами вводных данных, включая изображения и видео. Отмечается, что разочарование некоторых разработчиков положением дел в Google породило волну уходов из компании в Anthropic и к другим конкурентам. Netflix сообщила о применении генеративного ИИ почти в 300 проектах
17.07.2026 [06:07],
Анжелла Марина
Компания Netflix сообщила, что около 300 фильмов и сериалов, доступных на стриминговой платформе, создавались с применением генеративного искусственного интеллекта. Это позволило ускорить производство контента, одновременно повысив качество результатов и снизив затраты. 
Источник изображения: Venti Views/Unsplash Информация прозвучала в финансовом отчёте Netflix за второй квартал, опубликованном в четверг. Компания уточнила, что в большинстве случаев ИИ применялся на этапе постпродакшна. В качестве примеров проектов названы Glory, Brasil 70: A Saga do Tri и The American Experiment, в которых искусственный интеллект использовался при создании сложных сцен, включая массовки, исторические сражения и общие планы вымышленных миров. Ранее генеральный директор Netflix Тед Сарандос (Ted Sarandos) также сообщал, что ИИ применялся при создании одной из сцен научно-фантастического сериала The Eternaut. Параллельно Netflix продолжает наращивать инвестиции в ИИ-технологии и всё активнее интегрирует их в производственный процесс. Недавно компания приобрела ИИ-стартап Бена Аффлека (Ben Affleck), открыла собственную студию ИИ-анимации, а также использовала сгенерированный ИИ голос Джина Уайлдера (Gene Wilder) в новом реалити-шоу Wonka’s The Golden Ticket. Согласно отчёту, Netflix получила выручку в размере $12,56 млрд, заявив, что по-прежнему планирует удвоить свои доходы от рекламы до $3 млрд. Кроме того, как пишет The Verge, зрители за последний отчётный период просмотрели более 97 млрд часов контента, что на 2 % больше, чем годом ранее. Параллельно платформа продолжает расширять ассортимент контента, добавляя видеоподкасты, короткие ролики в формате TikTok и готовится к показу видеоматериалов цифровых медиабрендов, включая BuzzFeed. Nvidia представила компактные компьютеры Jetson T3000 и T2000 на чипах Blackwell для роботов
16.07.2026 [15:52],
Николай Хижняк
Компания Nvidia анонсировала две компактные вычислительные платформы Jetson Thor для роботов, промышленного оборудования и других периферийных систем искусственного интеллекта. Модели Jetson T3000 и T2000 планируется выпустить в первом квартале 2027 года. 
Источник изображений: Nvidia Платформа Jetson Thor T3000 использует графический процессор Nvidia Blackwell и восьмиядерный процессор Arm Neoverse. Она обеспечивает производительность ИИ на уровне 865 FP4 TFLOPS. Система оснащена 32 Гбайт памяти LPDDR5X с пропускной способностью 273 Гбайт/с и поддерживает сетевое подключение со скоростью до 25 Гбит/с. 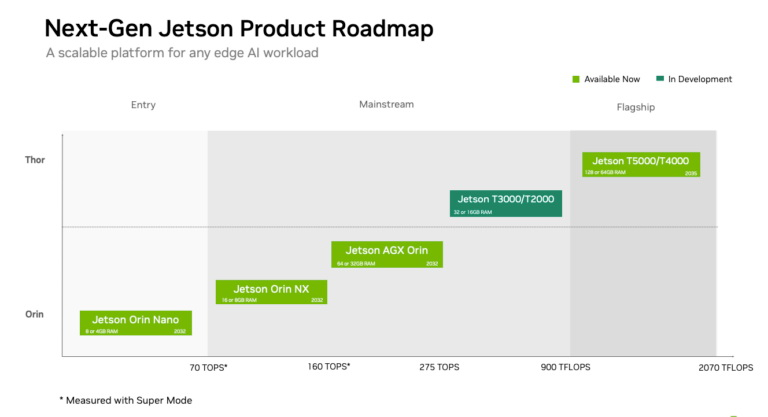 Nvidia заявляет, что T3000 примерно вдвое компактнее и потребляет примерно вдвое меньше энергии, чем существующий модуль T5000. Несмотря на уменьшение размеров, компьютер может обеспечить аналогичную производительность при выполнении таких задач, как обработка естественного языка, компьютерное зрение и моделирование робототехнических систем, отмечает Nvidia. Jetson Thor T2000 — это более доступный вариант с производительностью 400 FP4 TFLOPS, оснащённый 16 Гбайт памяти. Nvidia ожидает, что этот компьютер будет использоваться в системах компьютерного зрения, мобильных роботах, промышленных манипуляторах и других машинах, которым не требуется производительность уровня T3000.  Разработчики смогут эмулировать T3000 уже в конце этого месяца, используя JetPack 7.2.1 и текущий комплект разработчика Jetson AGX Thor. Эмуляция T2000 появится позже, а выпуск физических модулей T3000 и T2000 запланирован на первый квартал 2027 года. Стартап бывшего технического директора OpenAI Миры Мурати выпустил первую ИИ-модель
16.07.2026 [06:12],
Анжелла Марина
Стартап Thinking Machines Lab выпустил свою первую ИИ-модель Inkling, предназначенную для широкого использования. Новинка позиционируется как универсальная модель с открытыми весами, сочетающая производительность и эффективность при обработке запросов различных типов. 
Источник изображения: AI Inkling поддерживает работу с разными форматами данных, а также позволяет разработчикам загружать и адаптировать модель под собственные задачи. При этом открытыми являются только её веса, а обучающие данные и исходный код компания не раскрывает. По заявлению разработчика, модель демонстрирует конкурентоспособные результаты по ряду тестов среди систем с открытыми весами, хотя и не претендует на статус самой производительной модели среди открытых и закрытых аналогов. Основанная в феврале прошлого года Мирой Мурати (Mira Murati) совместно с бывшими сотрудниками OpenAI, Thinking Machines входит в число новых ИИ-стартапов, разрабатывающих системы, способные конкурировать с OpenAI и Anthropic. Ещё до выпуска первого продукта компания привлекла $2 млрд при оценке в $12 млрд, после чего приступила к обсуждению проведения нового инвестиционного раунда. За это время часть сотрудников покинула стартап, перейдя в Meta✴✴ и OpenAI. Как отмечает Bloomberg, выпуск Inkling может частично заполнить нишу на американском рынке открытых ИИ-моделей, где разработчики уступают китайским конкурентам. При этом Meta✴✴ постепенно смещает внимание в сторону закрытых моделей, а OpenAI, несмотря на выпуск двух открытых моделей в прошлом году, по-прежнему делает основной акцент на платных продуктах. В настоящее время Thinking Machines не планирует монетизировать свою модель. Основным источником дохода компании останется инструмент Tinker, предназначенный для тонкой настройки ИИ-моделей и используемый, в частности, компанией Bridgewater Associates для повышения эффективности моделей в решении финансовых задач. По словам Мурати, Inkling также является частью стратегии по созданию «моделей взаимодействия» (interaction models), позволяющих сделать совместную работу человека и искусственного интеллекта более естественной. «Сбер» представил платформу GigaCode Desktop для автоматизации задач силами ИИ-агентов
15.07.2026 [20:31],
Николай Хижняк
«Сбер» представил GigaCode Desktop — новое программное решение, использующее команду специализированных ИИ-агентов в едином интерфейсе. Приложение предназначено не только для генерации кода, но и для выполнения широкого спектра других задач с помощью различных ИИ-агентов. Продукт уже активно используется в банке и готовится к выходу на внешний рынок. 
Источник изображения: Steve Johnson / Unsplash GigaCode Desktop представляет собой экосистему узкоспециализированных ИИ-агентов, которые работают согласованно. Они способны совместно искать информацию, проводить анализ документов, составлять отчёты, подготавливать презентации, отслеживать прогресс и координировать свои действия. Такая автоматизация рутинных процессов позволяет пользователям сконцентрироваться на более сложных аналитических и творческих задачах. Решение предназначено не только для разработчиков, но и для бизнес-аналитиков, тестировщиков, менеджеров проектов, продуктовых менеджеров и специалистов по информационной безопасности. Внедрение GigaCode Desktop является частью реализации концепции AI-Disrupt PDLC, которая предусматривает создание комплексного портфеля инструментов Сбера для всех этапов разработки продукта. В текущую экосистему уже входят GigaCode (для генерации и анализа кода), GigaView (для анализа продуктивности разработчиков), GigaIDE (интегрированная среда разработки), GitVerse (платформа для совместной работы с кодом) и GigaStudio (система создания веб-приложений с помощью генеративного ИИ). «Значительная часть интеллектуального труда до сих пор состоит из операционной рутины: поиска информации, оформления документов, аналитики, подготовки отчётов и постоянного переключения между приложениями. На эти процессы уходит до половины рабочего времени. ИИ-агенты способны взять их на себя, экономя каждому сотруднику несколько часов в неделю. Для крупной компании это эквивалент тысяч дополнительных человеко-часов. При работе со сложными бизнес-процессами GigaCode Desktop переводит взаимодействие из формата отдельных диалогов в режим управления группой автономных агентов. Платформа ускоряет командную работу и органично дополняет линейку решений, заложенных в нашу концепцию AI-трансформации разработки программного обеспечения — AI-Disrupt PDLC», — прокомментировал старший вице-президент и руководитель блока «Технологии» Сбербанка Кирилл Меньшов. Google показала мультимодальную ИИ-модель для Pixel 10, которая работает без интернета
15.07.2026 [00:54],
Владимир Фетисов
Компания Google анонсировала ИИ-модель Gemma 4 E2B for TPU, которая прошла оптимизацию для ИИ-чипа, используемого в смартфонах серии Pixel 10. Алгоритмы Gemma представляют собой открытые ИИ-модели IT-гиганта, способные функционировать локально непосредственно на устройстве пользователя. Новый алгоритм Google представила в рамках мероприятия I/O India. 
Источник изображения: 9to5google.com Дебют ИИ-модели Gemma 4 состоялся в апреле этого года. Уже тогда Google заявила, что этот алгоритм станет основой для будущей Gemini Nano 4. Представленный на этой неделе вариант Gemma 4 E2B for TPU оптимизирован для работы на тензорном процессоре (TPU) G5. Google описывает алгоритм как «современную, мощную, но при этом удивительно лёгкую модель». Использовать её смогут владельцы смартфонов Pixel 10, Pixel 10 Pro, Pixel 10 Pro XL и Pixel 10 Pro Fold. Мультимодальная ИИ-модель, работающая локально на устройстве, способна справляться с выполнением разных задач без подключения к интернету. Среди прочего Google анонсировала ИИ-чат с быстрыми ответами и поддержкой длительных бесед, функцию определения объектов, растений и разного рода неисправностей автомобилей по фотографиям, а также возможность локальной расшифровки аудио, что может оказаться полезным для записи лекций, создания заметок и др. Ещё Google показала новые функции, такие как Mobile Actions, которые позволяют «управлять основными опциями смартфона, например Wi-Fi или картографическими данными, с помощью голосовых команд или текста» локально. Алгоритм может на основании озвученного пользователем рецепта какого-либо блюда сформировать локализованный список покупок ингредиентов в режиме офлайн или по фотографии неисправных деталей автомобиля провести диагностику. Anthropic пошла на попятную и вернула Claude Fable 5 в подписку для платных пользователей
13.07.2026 [12:51],
Владимир Фетисов
Хорошая новость для тех, кто планировал начать работу с новейшей ИИ-моделью Claude Fable 5 от Anthropic, но откладывал это из-за путаницы с доступностью сервиса. Разработчик предоставил платным подписчикам возможность взаимодействия с ИИ-моделью без дополнительной платы, по крайней мере временно. 
Источник изображения: anthropic.com Запуск Fable 5 оказался удивительно запутанным. Anthropic представила решение в качестве своей флагманской модели. Однако из-за экспортных ограничений доступ к продукту в ряде стран был невозможен, а когда модель стала общедоступной, то компания объявила о переходе на оплату по количеству используемых токенов. Такой подход означает, что даже подписчики Claude Pro и других премиальных тарифов будут платить ещё больше, взаимодействуя с Fable 5. Не удивительно, что подписчики выразили недовольство изменением подхода Anthropic к взиманию платы за использование передовой ИИ-модели. В результате Anthropic смягчила свою позицию, объявив, что Fable 5 останется доступной платным подписчикам на прежних условиях до 19 июля 2026 года. Вместе с этим компания объявила о сохранении повышенных еженедельных лимитов на использование Claude Code ещё на неделю. Поскольку Anthropic продлила пробный период использование Fable 5, платные подписчики могут не переплачивая продолжить взаимодействие с передовой моделью для генерации программного кода, проведения исследований и др. Однако важно помнить, что Fable 5 расходует недельный лимит токенов значительно быстрее, чем другие модели семейства. Это означает, что при активной работе с системой пользователю придётся рано или поздно переключиться на работу с другой ИИ-моделью или же отдельно докупать токены. ИИ нанёс японским знаменитостям ущерб на $31 млн всего за два месяца
10.07.2026 [17:08],
Анжелла Марина
Исследование японской некоммерческой организации по защите авторских прав известных личностей Japro показало, что за два месяца 2025 года были выявлены более 43 тыс. предполагаемых случаев нарушения авторских и смежных прав с использованием искусственного интеллекта. По оценке Japro, связанные с этим финансовые потери знаменитостей и артистов достигли 4,5 млрд йен. 
Источник изображения: AI Согласно исследованию, проведённому на основе данных различных социальных платформ, к числу нарушений относятся создание с помощью ИИ игровых экранизаций аниме с использованием изображений знаменитостей, а также генерация голосов персонажей аниме для исполнения популярных песен. Такой контент, как сообщает издание The Japan Times, суммарно набрал около 335 млн просмотров, а расчёт предполагаемого ущерба основывался на стоимости лицензирования изображения или голоса, а также рекламной ценности полученной аудитории. В Japro отметили, что фактический размер убытков может оказаться значительно выше приведённых оценок, поскольку анализ охватывал только обнаруженные случаи. Одновременно опрос 174 компаний индустрии развлечений показал, что лишь около 28 % респондентов полностью или частично осведомлены о масштабах подобных нарушений, тогда как многие указали на невозможность отследить все незаконные случаи использования образов артистов. Кроме того, только 1,1 % опрошенных компаний сообщили о наличии внутренних рекомендаций по реагированию на подобные нарушения. При этом 52 % заявили, что продолжают рассматривать возможные меры, а остальные пока не планируют разрабатывать соответствующие правила. На фоне растущих опасений Министерство юстиции Японии сформировало экспертную группу для обсуждения возможных правовых мер в отношении ИИ-контента, при этом главный антимонопольный и административный орган Японии Japan Fair Trade Commission (JFTC) с декабря прошлого года изучает использование новостных материалов поисковыми ИИ-ботами без разрешения правообладателей. ИИ породил новый дефицит: в США перестало хватать силовых трансформаторов
10.07.2026 [13:36],
Владимир Фетисов
Повсеместный спрос на трансформаторы, являющиеся ключевым элементом любой электросети, и их нехватка угрожают планам IT-гигантов по вводу в эксплуатацию новых центров обработки данных для нужд искусственного интеллекта. Отмечается, что дефицит трансформаторов буквально «душит» развитие сферы ИИ в США. 
Источник изображения: Matt Richmond/unsplash.com В электросетях, используемых для питания крупных ЦОД, устанавливаются огромные трансформаторы, которые весят сотни тонн и могут одновременно обеспечивать электроэнергией до 25 млн iPhone. Прочная конструкция таких устройств позволяет им функционировать десятилетиями с минимальным техническим обслуживанием. При этом чаще всего такие трансформаторы изготавливаются на заказ, а сам процесс занимает от трёх до шести месяцев. Отраслевые аналитики считают, что дефицит трансформаторов будет сохраняться как минимум до 2030 года. Аналитики компании SynMax подсчитали, что около 40 % новых ЦОД в США, которые планируется ввести в эксплуатацию в этом году, будут запущены с опозданием. Причиной этого могут стать именно проблемы с электроснабжением и поставками электрооборудования. Отмечается, что требования к мощности электросетей выросли настолько, что американский бизнесмен Илон Маск (Elon Musk) и руководители других IT-компаний рассматривают перспективы строительства ЦОД на околоземной орбите, где для непрерывного питания могла бы использоваться солнечная энергия. В дополнение к этому наблюдается нехватка специальной электротехнической стали, являющейся незаменимым материалом для изготовления сердечников трансформаторов и производимой лишь несколькими поставщиками по всему миру. Дополнительное негативное воздействие оказывают волатильность цен и ограниченность возможностей добычи, что влияет на цепочки поставок меди, необходимой для изготовления обмоток трансформаторов. Ещё одной серьёзной проблемой в производстве трансформаторов является нехватка персонала, способного выполнять сложные задачи. Производители трансформаторов, такие как Hitachi, Siemens Energy и GE Vernova, пытаются улучшить ситуацию, вкладывая сотни миллионов долларов в расширение производственной инфраструктуры. Администрация президента США ввела в действие Закон об оборонном производстве (Defense Production Act), предусматривающий присвоение цепочкам поставок для электросетей страны статуса «критически ограниченных» и позволяющий Министерству энергетики выдавать займы и применять другие меры поддержки местных производителей электрооборудования. По данным источника, американским покупателям трансформаторов уже скоро придётся прибегнуть к импорту. Страны Евросоюза, а также Мексика, Южная Корея и Бразилия являются крупнейшими поставщиками трансформаторов на рынок США с суммарной долей более 75 %. При этом IT-гиганты, такие как Amazon, Meta✴✴, Alphabet и Microsoft, уже стали крупнейшими покупателями электрооборудования и планируют дальнейшее увеличение расходов на развитие электросетей. В этом году американские компании планируют суммарно потратить на трансформаторы и сопутствующее оборудование для расширения ИИ-инфраструктуры $726 млрд. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



