|
Опрос
|
реклама
Быстрый переход
Режим ChatGPT «для взрослых» дебютирует не ранее следующего квартала
12.12.2025 [06:58],
Алексей Разин
Появление у ChatGPT способности вести разговоры на откровенные темы, как отмечали представители OpenAI ранее, должно было совпасть по времени с внедрением механизма защиты от доступа к нему несовершеннолетних. Если ранее в качестве срока фигурировал декабрь этого года, то теперь OpenAI считает, что соответствующие функции появятся не ранее первого квартала следующего года. 
Источник изображения: OpenAI Директор OpenAI по приложениям Фиджи Симо (Fidji Simo) заявила в этот четверг на брифинге, посвящённом ChatGPT-5.2, что «режим для взрослых» будет представлен в чат-боте в первом квартале 2026 года, поскольку компания сперва рассчитывает внедрить улучшенные механизмы предсказания возраста пользователей. Сейчас этот механизм проходит стадию раннего тестирования в отдельных странах, он должен позволить чат-боту автоматически применять ограничения, позволяющие исключить доступ несовершеннолетних к неподобающему контенту. При этом в OpenAI считают важным обеспечить высокую точность определения возраста пользователя, чтобы не допустить злоупотребления со стороны подростков, а с другой стороны — не ограничивать в правах зрелых пользователей по ошибке. К внедрению подобных механизмов верификации возраста пользователей разработчиков приложений по всему миру подталкивают новые законодательные ограничения, направленные на защиту психического здоровья молодого поколения пользователей онлайн-сервисов. В этих изысканиях OpenAI не уникальна, и необходимость внедрения таких механизмов обусловлена угрозой присуждения крупных штрафов за нарушения в этой сфере. «Красный код» сработал: OpenAI ускорилась и выпустила «лучшую на сегодня» GPT-5.2
12.12.2025 [00:48],
Андрей Созинов
OpenAI выпустила GPT-5.2 — новую версию передовой модели ИИ, которую компания назвала «лучшей на сегодня» для повседневной профессиональной работы. Анонс последовал спустя месяц после выхода GPT-5.1 на фоне обострения конкуренции с Google (в частности, с моделью Gemini 3) и Anthropic. 
Источник изображений: OpenAI Срочное обновление появилось после объявления в OpenAI «красного кода»: в начале месяца глава OpenAI Сэм Альтман (Sam Altman) призвал сотрудников сосредоточить усилия на улучшении ChatGPT, отодвинув на второй план остальные задачи.  GPT-5.2, по заявлению OpenAI, превосходит предшественников в четырёх областях: построение таблиц и работа с данными, создание презентаций, восприятие и анализ изображений, а также написание кода и работа с длинным контекстом. Модель доступна в ChatGPT в трёх вариантах: Instant, Thinking и Pro. GPT‑5.2 Instant — это быстрый и мощный инструмент для повседневной работы и обучения. В этой версии был улучшен поиск информации, работа с инструкциями, техническое письмо и перевод. Также отмечается улучшенные пошаговые объяснения ответов. И всё это основано на более теплом тоне общения, представленном в GPT‑5.1 Instant. Первые тестировщики особо отметили более четкие объяснения, в которых ключевая информация выделяется сразу. Тесты GPT-5.2
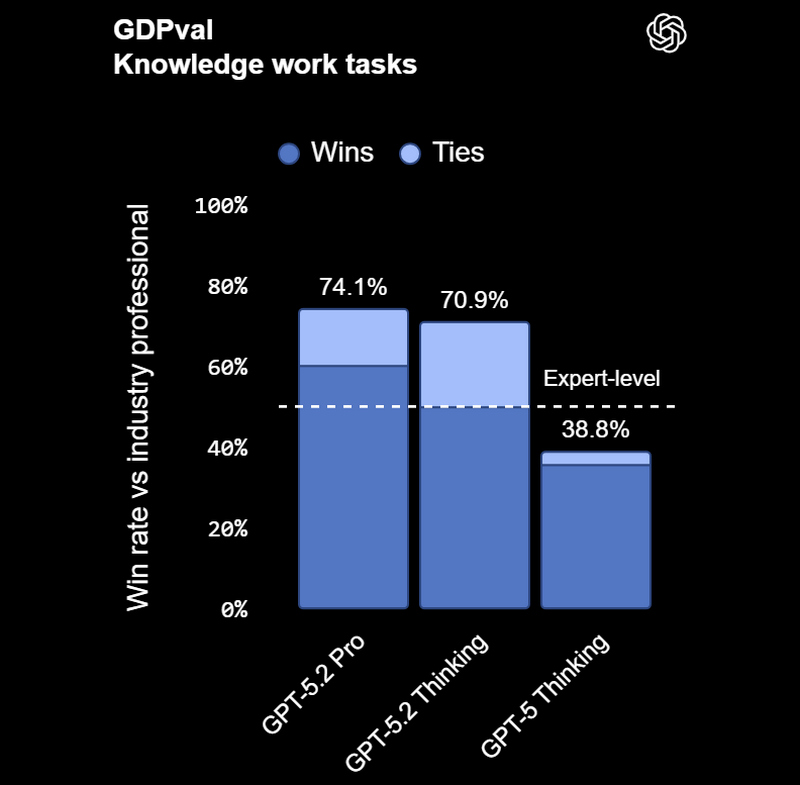
Смотреть все изображения (5)
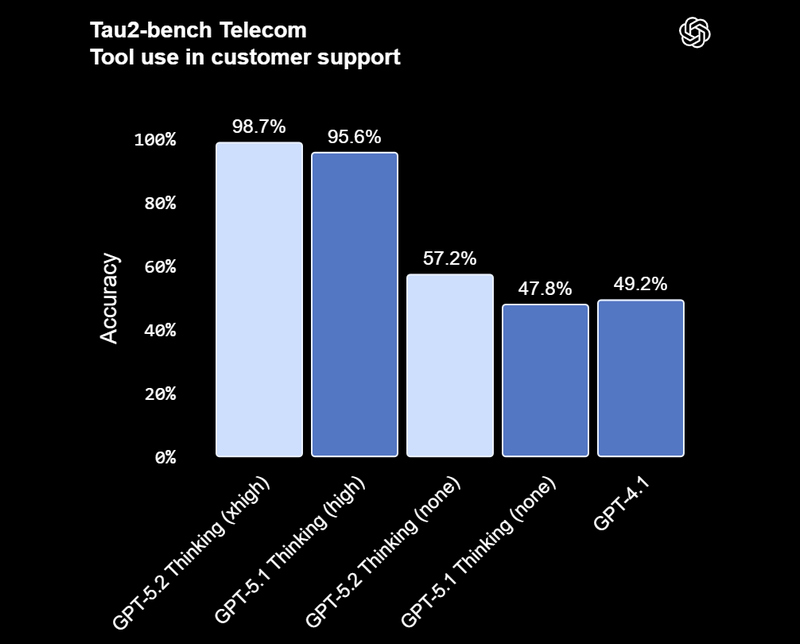
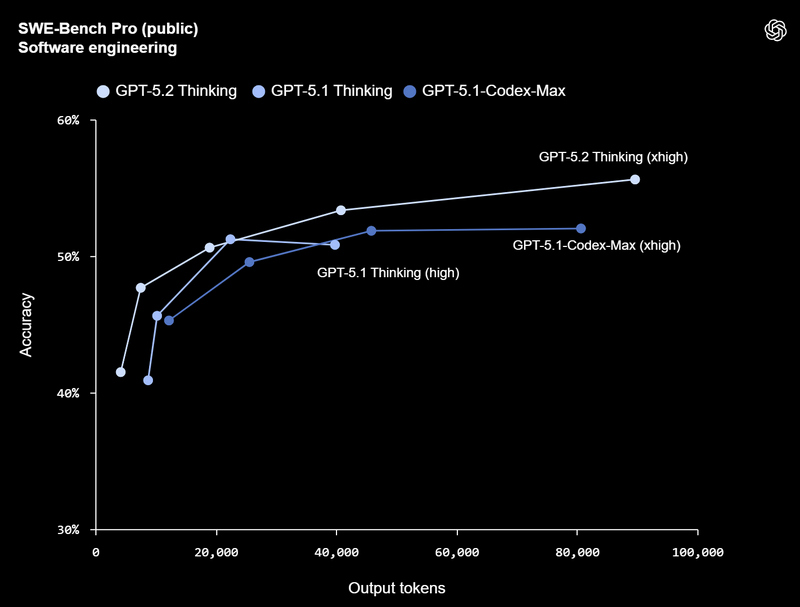
Смотреть все изображения (5) Версия GPT‑5.2 Thinking предназначена для более глубокой работы с запросами, решения более сложных задач с большей точностью. По данным разработчиков, эта модель особенно хороша в области написания кода, составления конспектов из длинных документов, ответов на вопросы о загруженных файлах, пошагового решения математических и логических задач, а также планирования и принятия решений с помощью более четкой структуры и более полезных деталей. GPT‑5.2 Pro описывается как самый умный и надежный вариант для сложных вопросов, где стоит подождать более качественного ответа. Ранние тесты показали меньшее количество серьезных ошибок и более высокую производительность в сложных областях, таких как программирование. 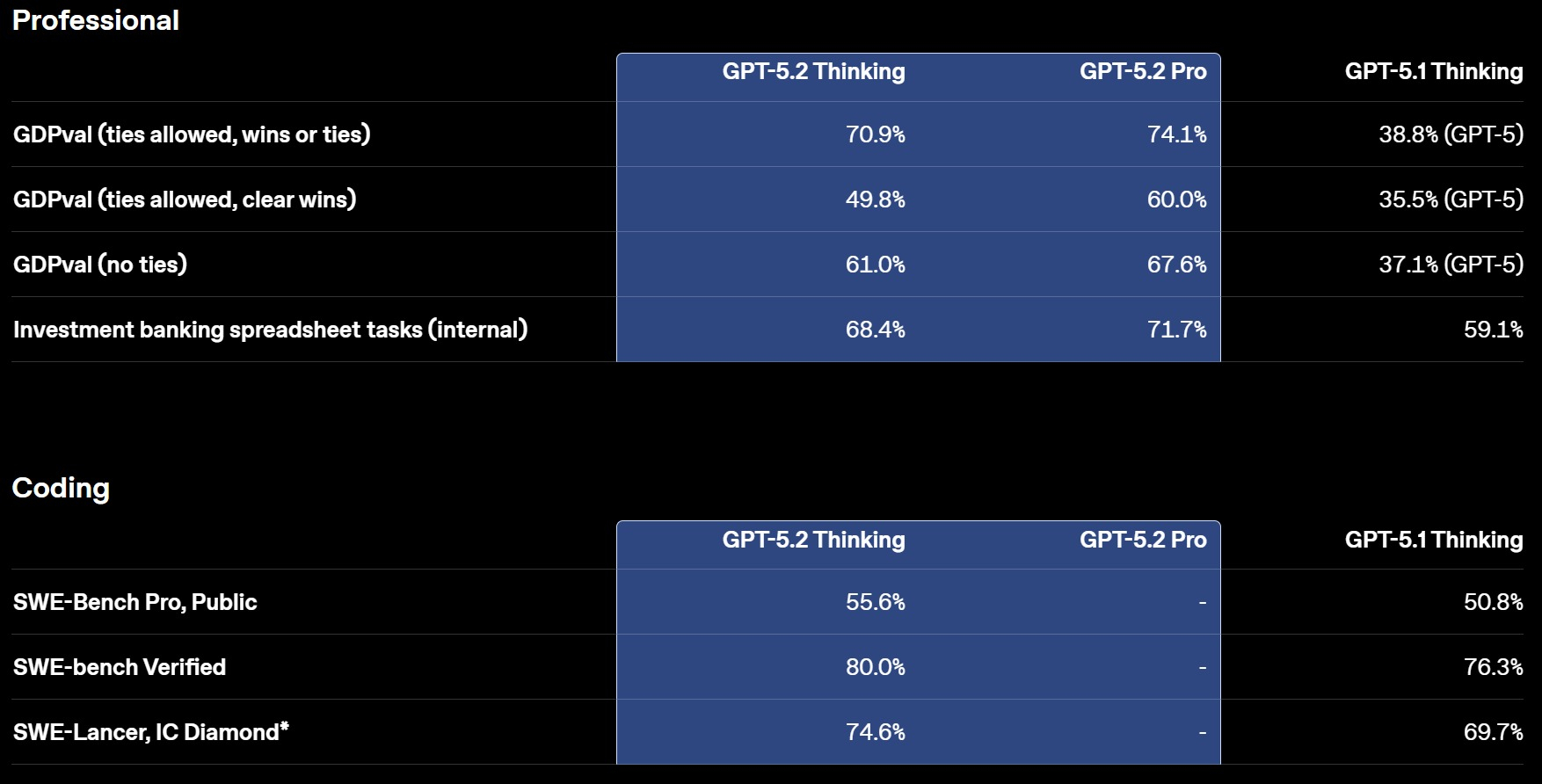 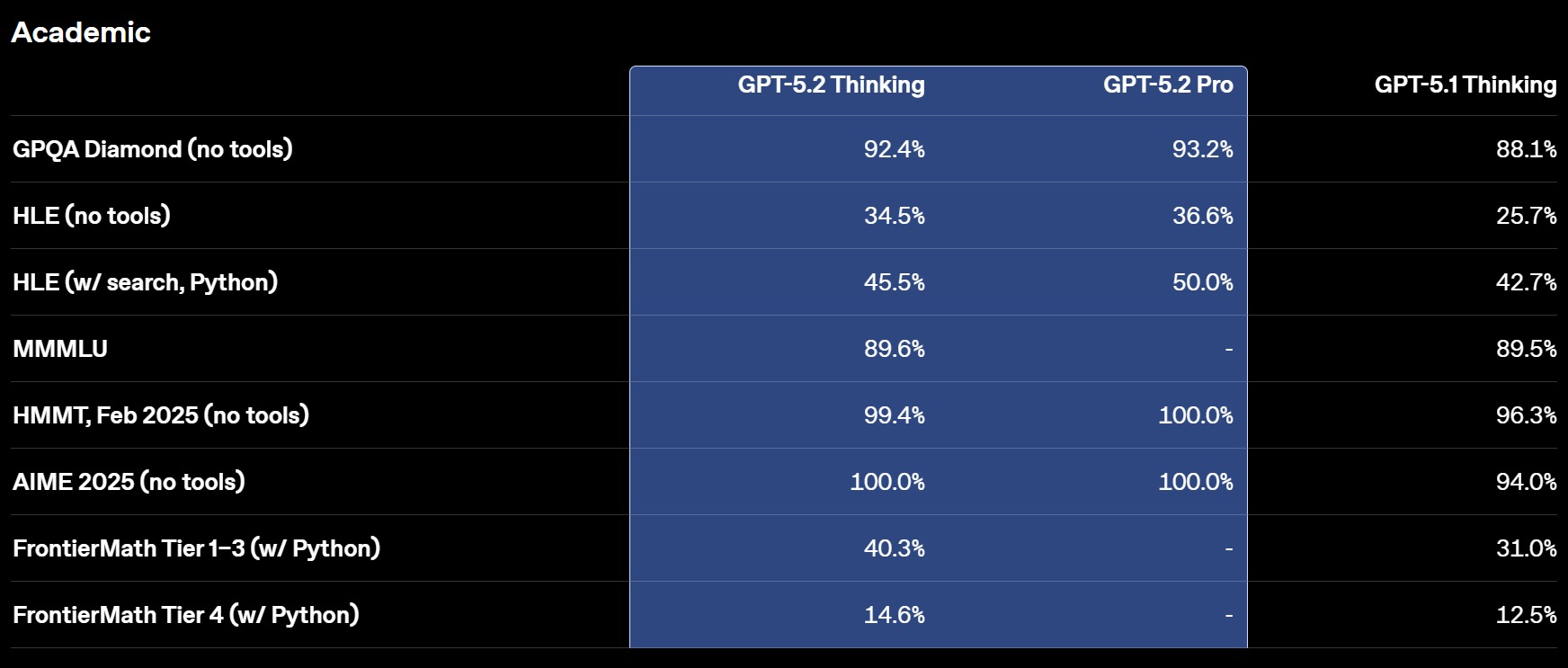 OpenAI утверждает, что GPT-5.2 Thinking даёт более точные ответы, чем люди-профессионалы, в 71 % задач по 44 отраслям. Также она генерирует на 38 % меньше галлюцинаций, чем её предшественница GPT-5.1. Также GPT-5.2 Thinking установила новые рекорды в бенчмарках, включая SWE-Bench Pro (в агентном кодировании) и GPQA Diamond (в научном мышлении). 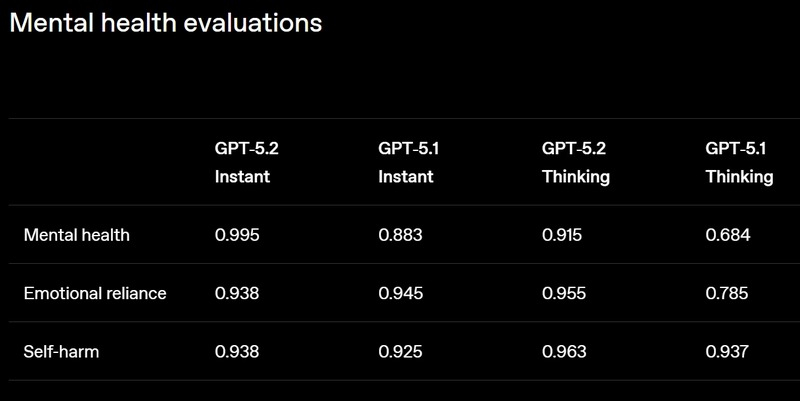 Кроме этого, OpenAI усилила обработку чувствительных запросов, связанных с суицидальными мыслями, психическим здоровьем и эмоциональной зависимостью от ИИ, а также начала внедрение системы оценки возраста для автоматической фильтрации контента для несовершеннолетних. GPT-5.2 уже доступна для платных пользователей ChatGPT (Plus, Pro, Enterprise) и через API для разработчиков. Доступ более широкой аудитории к новой модели будет открываться постепенно с завтрашнего дня. Генеративный Микки Маус грядёт: Sora сможет создавать видео с героями Disney, Marvel, Pixar и Star Wars, а OpenAI получит $1 млрд
11.12.2025 [20:03],
Андрей Созинов
The Walt Disney Company и OpenAI заключили трёхлетнее лицензионное соглашение, которое позволит ИИ-генератору видео Sora создавать ролики с более чем 200 персонажами вселенных Disney, Marvel, Pixar и Star Wars. Кроме того, Disney инвестирует в разработчика ChatGPT по меньшей мере $1 млрд. 
Источник изображения: OpenAI В рамках соглашения OpenAI получит лицензию на использование контента одного из крупнейших медиа-холдингов мира. Соглашение охватывает широкий набор визуальных образов — от персонажей и костюмов до транспортных средств и даже локаций. При этом условия сделки подчёркивают: лицензия не распространяется на любые голоса или внешность реальных актёров. В итоге пользователи Sora смогут создавать короткие ролики по текстовому описанию с участием более чем 200 персонажей, принадлежащих Disney. Также этих персонажей можно будет использовать при генерации изображений через ChatGPT Images. Первые ролики и изображения с лицензионными персонажами появятся в начале 2026 года. Среди доступных для генерации образов будут Микки и Минни Маус, герои «Холодного сердца», «Истории игрушек», «Короля Льва», «Вверх», «Зверополиса» и многих других франшиз. Пользователи также смогут создавать видео и изображения с культовыми персонажами Marvel и Lucasfilm — включая Капитана Америку, Чёрную пантеру, Дэдпула, Грута, Железного человека, Локи, Мандалорца, Йоду, Дарта Вейдера, Люка Скайуокера и других. С другой стороны, Disney в рамках партнёрства получит доступ к OpenAI API для разработки новых продуктов и инструментов, включая будущие функции для Disney+. Также планируется интеграция Disney+ с Sora: отобранные ролики, созданные пользователями, будут появляться на платформе в виде отдельного раздела, что станет одним из первых примеров использования ИИ-контента в большом стриминговом сервисе. Помимо лицензионных условий компании объявили и о финансовой части сделки: Disney инвестирует в OpenAI $1 млрд и получит варранты на приобретение дополнительной доли в компании. По словам сторон, это создаёт долгосрочный фундамент для совместной разработки инструментов, связанных с персонализацией, рекомендациями и созданием нового пользовательского опыта на базе ИИ. В совместном заявлении Disney и OpenAI отмечают, что развитие генеративных технологий должно учитывать интересы авторов и безопасность пользователей. Компании обязались поддерживать механизмы, предотвращающие создание незаконного или вредоносного контента, а также обеспечивать защиту интеллектуальной собственности и персональных данных — включая право на контроль над использованием голоса и внешности. OpenAI также подтвердила, что продолжит внедрять возрастные ограничения и другие меры безопасности, которые должны снизить риски при работе с генеративными моделями. Генеральный директор Disney Боб Айгер (Bob Iger) назвал сотрудничество «важным моментом для всей индустрии», подчеркнув, что ИИ уже влияет на способы создания и распространения контента. «Сочетание культовых историй и персонажей Disney с передовыми технологиями OpenAI даст поклонникам Disney возможность проявить воображение и творческий потенциал так, как никогда раньше, предоставляя им новые способы взаимодействия с любимыми персонажами и историями Disney», — заявил он. Глава OpenAI Сэм Альтман (Sam Altman), в свою очередь, отметил, что партнёрство демонстрирует, как ИИ-компании могут сотрудничать с создателями контента, сохраняя уважение к творческим правам. «Disney — мировой эталон в области повествования, и мы рады сотрудничеству, которое позволит Sora и ChatGPT Images расширить возможности людей в создании и восприятии великолепного контента», — сказал Альтман. «Мы можем ошибиться»: Сэм Альтман признал, что ИИ развивается слишком быстро
10.12.2025 [18:36],
Сергей Сурабекянц
Глава OpenAI Сэм Альтман (Sam Altman) недавно выразил обеспокоенность темпами, с которыми ИИ меняет мир, подчеркнув важность и необходимость адаптации общества. По его словам, ни одна другая технология никогда не внедрялась в мире так быстро. Он признал, что ChatGPT обладает огромным потенциалом для исследователей, но в то же время может быть использован злоумышленниками для причинения глобального вреда человечеству. 
Источник изображения: The Tonight Show За последние три года генеративный ИИ эволюционировал от простых чат-ботов, способных создавать картинки и тексты на основе подсказок, до сложных инструментов повышения производительности, оказывающих реальное влияние на общество в медицине, образовании, вычислительной технике и других сферах. Однако это сопряжено с невероятными затратами, непомерным спросом на охлаждение и электроэнергию, и с негативным воздействием на окружающую среду. В своём недавнем интервью Альтман выделил длинный список недостатков широкого распространения и роста ChatGPT, включая скорость, с которой он изменил мир. По его словам, ChatGPT обладает потенциалом для разработки лекарств от сложных медицинских заболеваний, таких как рак, но в то же время он может быть использован злоумышленниками для причинения вреда, с которым общество может не справиться. «Меня беспокоят темпы изменений, происходящих в мире прямо сейчас. Этой технологии [ИИ] всего три года. Ни одна другая технология никогда не внедрялась в мире так быстро», — заявил Альтман. И следом добавил: «Мы должны убедиться, что мы представляем это [ИИ] миру ответственно, давая людям время адаптироваться, высказать свое мнение, понять, как это сделать — можно представить, что мы можем ошибиться». ChatGPT сейчас является самым скачиваемым приложением в мире с примерно 1,36 миллиардами установок с момента его запуска в ноябре 2022 года. Среди аналитиков и экспертов нарастают опасения о формировании зависимости людей от чат-ботов, что приводит к атрофии когнитивных способностей пользователей и делает их глупее. Также сообщается, что за последние несколько месяцев увеличилось число самоубийств, связанных с чрезмерной зависимостью от инструментов на основе ИИ, подобных ChatGPT. — ChatGPT вырос в восемь раз: OpenAI показала, почему её планы стоят $1,4 трлн
08.12.2025 [19:59],
Сергей Сурабекянц
Через неделю после того, как Сэм Альтман (Sam Altman) разослал служебную записку о «красном коде» из-за конкурентной угрозы со стороны Google, OpenAI опубликовала данные, свидетельствующие о резком росте использования её инструментов ИИ за последний год. По утверждению компании результаты превосходные: объём сообщений ChatGPT вырос в восемь раз с ноября 2024 года, а сотрудники компаний, внедривших чат-бот, экономят до часа времени ежедневно. 
Источник изображения: unsplash.com OpenAI вынуждена переосмысливать свою позицию лидера в области корпоративного ИИ из-за растущего конкурентного давления. Хотя, согласно индексу Ramp AI, почти 36 % американских компаний являются клиентами ChatGPT Enterprise по сравнению с 14,3 % у Anthropic, большая часть выручки OpenAI по-прежнему поступает от потребительских подписок — базы, которая находится под угрозой со стороны Google Gemini. Кроме того, OpenAI всё чаще приходится сталкиваться с поставщиками открытых моделей ИИ для корпоративных клиентов. В общей сложности OpenAI рассчитывает на инвестиции в размере $1,4 трлн на развитие инфраструктуры ИИ в течение следующих нескольких лет, что делает рост корпоративных клиентов неотъемлемой частью её бизнес-модели. «С точки зрения экономического роста, потребители действительно важны, — заявил главный экономист OpenAI Ронни Чаттерджи (Ronnie Chatterji). — Но если посмотреть на исторически революционные технологии, такие как паровой двигатель, то именно внедрение и масштабирование этих технологий компаниями приносит наибольшие экономические выгоды». Данные, предоставленные OpenAI, показывают, что внедрение технологий среди крупных предприятий не только растёт, но и становится более интегрированным в рабочие процессы. Организации, использующие API OpenAI, потребляют в 320 раз больше «токенов рассуждений», чем год назад, что косвенно говорит о применении ИИ для решения более сложных задач. Однако, это может подтверждать лишь факт активных экспериментов с новой технологией, которые не приносят долгосрочной выгоды. К тому же, рост числа токенов логического мышления коррелирует с ростом энергопотребления и может дорого обходиться клиентам. OpenAI также описала изменения в использовании её инструментов корпоративными клиентами. Использование ИИ-помощников для автоматизации рабочих процессов выросло за последний год в 19 раз и теперь на них приходится 20 % корпоративных сообщений. «Это показывает, насколько люди способны использовать эту мощную технологию и адаптировать её под свои нужды», — заявил главный операционный директор OpenAI Брэд Лайткап (Brad Lightcap). 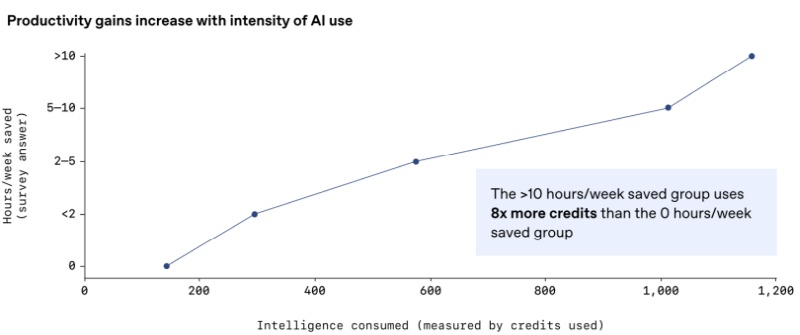
Источник изображений: OpenAI По данным OpenAI, интеграции ИИ привели к значительной экономии времени. Клиенты сообщили об экономии от 40 до 60 минут в день благодаря корпоративным продуктам OpenAI, хотя эта экономия может не отражать время, затрачиваемое на изучение систем, написание подсказок или проверку результатов ИИ. В отчёте OpenAI отмечается, что сотрудники предприятий все чаще используют инструменты ИИ для расширения своих возможностей. По утверждению компании, три четверти опрошенных утверждают, что ИИ позволяет им решать задачи, в том числе технические, которые они раньше не могли выполнять. OpenAI сообщила о 36-процентном увеличении количества сообщений, связанных с программированием, за пределами инженерных, ИТ- и исследовательских групп. Хотя OpenAI продвигает идею о том, что её технология расширяет возможности сотрудников, стоит отметить, что написание кода при помощи чат-бота может привести к увеличению числа уязвимостей безопасности и сложностям при доработках программ. Для обнаружения ошибок, уязвимостей и эксплойтов и решения других проблем компания выпустила агентский инструмент исследования безопасности Aardvark, который сейчас находится на стадии закрытого бета-тестирования. 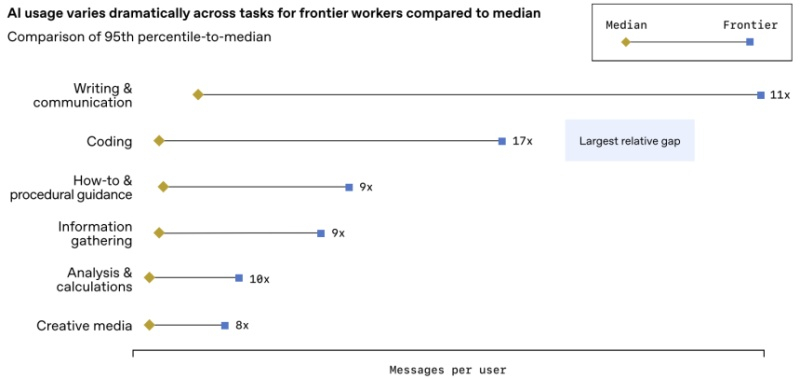 Лайткап и Чаттерджи подчеркнули «растущий разрыв во внедрении ИИ», при этом некоторые «передовые» сотрудники чаще используют больше инструментов, чем «отстающие». «Есть компании, которые до сих пор воспринимают эти системы как программное обеспечение, что-то, что я могу купить, предоставить своим командам, и на этом всё заканчивается, — сказал Лайткап. — А есть компании, которые действительно начинают его использовать, почти как операционную систему. По сути, это реплатформинг многих операций компании». По мнению OpenAI, даже самые активные пользователи ChatGPT Enterprise не используют все доступные им передовые инструменты, такие как дата-майнинг, логический анализ или поиск. Лайткап полагает, что полное внедрение систем ИИ требует существенного изменения мышления сотрудников и более глубокой интеграции ИИ с корпоративными данными и процессами. Потребуется время, чтобы лучше понять возможности и перестроить рабочие процессы. Инвесторы охладели к OpenAI, фаворитом в сфере ИИ становится Google
08.12.2025 [07:04],
Алексей Разин
По мнению опрошенных Bloomberg экспертов фондового рынка, корпорация Google постепенно притягивает к себе всё больше внимания в сегменте ИИ, тогда как разработавший ChatGPT стартап OpenAI уходит на второй план. Он хотя и не является публичной компанией, собрал вокруг себя достаточно партнёров, чьи акции торгуются на бирже. 
Источник изображений: Google Инвесторов, как поясняет источник, всё больше беспокоят растущие расходы OpenAI без видимых перспектив скорейшего получения прибыли, которая к тому же должна расти очень быстро для создания условий для окупаемости. Холдинг Alphabet, в который входит Google, при этом может похвастать наличием прибыльного бизнеса, позволяющего финансировать проекты в сфере ИИ. Котировки акций эмитентов, находящихся в орбите интересов OpenAI, начали проседать. Об этом можно судить по динамике курса ценных бумаг Oracle, CoreWeave, AMD, Microsoft, Nvidia и SoftBank. При этом акции Broadcom, Lumentum, Celestica и TTM Technologies на подъёме, поскольку бизнес этих компаний связан с активностью Alphabet в сфере ИИ. Если ранее любая благоприятная активность OpenAI способствовала росту курса акций своих сателлитов, то теперь такая связь становится для соответствующих эмитентов своего рода якорем, сдерживающим положительную динамику ценных бумаг. Перемены реализовались буквально в течение нескольких недель. Ещё недавно любой прогресс OpenAI вызвал серьёзный подъём котировок акций, связанных с её деятельностью. «Прозрению» инвесторов способствовали многочисленные комментарии экспертов, которые обратили внимание на «кольцевые схемы» финансирования, растущие долги и неуёмный аппетит стартапа. Если попавшие в сферу интересов OpenAI компании в текущем году увеличили свою капитализацию на 74 %, то в случае с Alphabet прирост измерялся более внушительными 146 %. Рост скептических настроений в отношении OpenAI впервые был зафиксирован в августе, поскольку новая модель GPT-5 удостоилась спорных оценок. В прошлом месяце Google представила новую версию своей Gemini, и тогда противопоставление с OpenAI дало перекос не в пользу последней. Обеспокоенность ситуацией выразил и генеральный директор OpenAI Сэм Альтман (Sam Altman), который объявил «красный код опасности» и велел подчинённым бросить все силы на улучшение ChatGPT. При этом Alphabet остаётся третьей по величине капитализации компанией в индексе S&P 500. У неё достаточно диверсифицированный бизнес, приносящий солидную прибыль во многих сферах деятельности. В сознании многих инвесторов растёт убеждение, что Alphabet имеет все составляющие для превращения в ведущего игрока сегмента ИИ. OpenAI в случае своего превращения во второго по величине игрока рискует финансовыми потоками, которые должны использоваться для оплаты услуг партнёров по развитию вычислительной инфраструктуры, начиная с Oracle и заканчивая AMD и Nvidia. Поставщики элементов инфраструктуры Google при этом демонстрируют отличную динамику своих акций. Поставляющая оптические решения для ЦОД компания Lumentum продемонстрировала рост капитализации более чем в три раза с начала этого года, Celestica прибавила 252 %, а участвующая в разработке фирменных чипов TPU компания Broadcom наблюдает рост котировок акций на 68 % с конца прошлого года.  Против OpenAI работает не только растущая конкуренция, многие инвесторы теперь опасаются, что амбиции стартапа слишком высоки для успешной реализации. Лидерство амбициозной компании теперь не столь очевидно, и это настораживает инвесторов. При этом глубокие взаимосвязи, которые OpenAI успела создать в отрасли, в случае краха её бизнеса угрожают всему фондовому рынку, и опасения по поводу формирования пузыря в сфере ИИ всё чаще звучат из уст экспертов. Сэма Альтмана предсказуемо раздражают подобные вопросы, и недавно он заявил, что «если кто-то желает продать свои акции, я найду на них покупателя», добавив, что не намерен больше рассуждать на эти темы. Эксперты HSBC подсчитали, что на интервале до 2033 года включительно расходы OpenAI способны превысить выручку стартапа на $207 млрд. В сложившейся ситуации для инвесторов находятся и положительные моменты. В частности, они могут приобрести по более низким ценам акции тех же Oracle и AMD, чей бизнес не завязан исключительно на OpenAI, и они в перспективе смогут неплохо себя чувствовать даже без сотрудничества с этим стартапом. Спросом будут пользоваться акции тех компаний, которые лучше конкурентов смогли монетизировать потенциал искусственного интеллекта. OpenAI заявила, что появившиеся в ChatGPT рекомендации по покупкам не являются рекламой
07.12.2025 [10:43],
Владимир Фетисов
Платные подписчики ChatGPT стали обращать внимание на появление новой подсказки с текстом «Купить товары для дома и продукты. Подключите Target», посредством которой можно связать свой аккаунт с розничной сетью Target, являющейся партнёром OpenAI. Многие восприняли данное сообщение как рекламу, но OpenAI это отрицает. 
Источник изображения: Nano Banana Pro / the-decoder.com Менеджер по продукту ChatGPT Ник Терли (Nick Turley) заявил, что компания «не проводит никаких тестов рекламы», добавив, что распространяющиеся в сети скриншоты «либо ненастоящие, либо не являются рекламой». Комментарии Терли косвенно указывают на то, что внутренние тесты рекламы всё же проводятся, несмотря на его заявление о том, что предложение связать свой аккаунт с платформой Target не нужно рассматривать как рекламу. Некоторые пользователи не готовы принять позицию OpenAI с учётом того, что появлявшееся на экранах их устройств сообщение выглядело как реклама. Главный научный сотрудник OpenAI Марк Чен (Mark Chen) был более осторожен в формулировках. Он признал, что сообщение от Target может показаться рекламой, добавив, что с подобными уведомлениями следует обращаться очень аккуратно. По словам Чена, OpenAI уже отключила демонстрацию подсказки с предложением связать свой аккаунт ChatGPT с сетью Target и теперь проводится работа по повышению точности модели, а также над внедрением настроек, которые позволят пользователям сократить или полностью отключить подобные рекомендации. 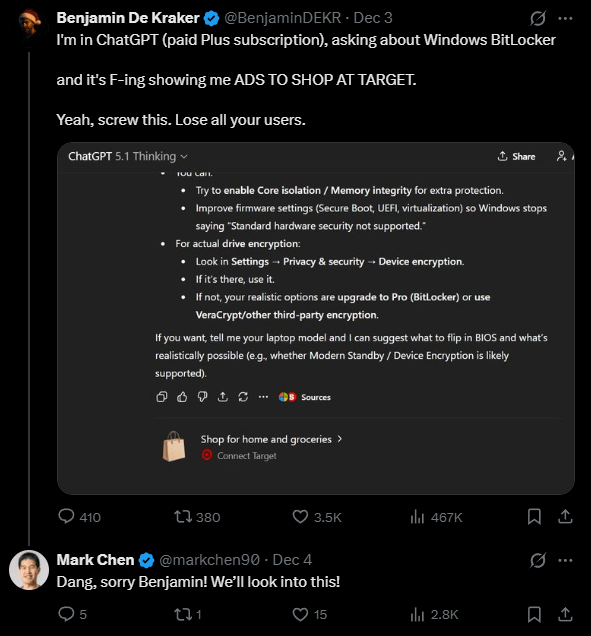
Источник изображения: X / the-decoder.com Более важный вопрос заключается в том, почему OpenAI так старательно подбирает формулировки для того, что для большинства пользователей выглядит как реклама. Поскольку примерно 95 % пользователей ChatGPT выбирают бесплатный тариф, компания испытывает серьёзное давление, стремясь монетизировать сервис, не оттолкнув при этом основную массу пользователей. Персонализированные предложения по покупкам были бы очевидным путём для увеличения доходов, но такой подход одновременно является весьма рискованным. Реклама внутри диалогового окна ИИ-бота сопряжена с другими рисками, нежели реклама в стандартной поисковой системе. Многие люди стали воспринимать ChatGPT как надёжного и даже личного помощника, поэтому любая его рекомендация имеет больше значения, чем обычная рекламная ссылка на странице поиска. Кроме того, гендиректор OpenAI Сэм Альтман (Sam Altman) в прошлом открыто предостерегал от превращения ChatGPT в рекламный инструмент. Он описывал будущее, в котором ChatGPT советует пользователям купить тот или иной продукт, как некую антиутопию. Теперь эти предостережения Альтмана выглядят всё более актуальными. Новый ИИ-агент OpenAI для поиска покупок Shopping Research использует систему памяти ChatGPT для персонализации рекомендаций по товарам. По данным источника, OpenAI также рассматривает возможность использования системы памяти ChatGPT для персонализированной рекламы. На этом фоне даже единожды появившееся сообщение с предложением купить что-либо в ChatGPT становится чем-то большим, чем просто эксперименты с интерфейсом. Это подчёркивает напряжённость между публичной позицией OpenAI в отношении рекламы и финансовым давлением, требующим монетизации огромной и преимущественно бесплатной пользовательской базы. Марк Цукерберг лично развозил домашний суп ИИ-специалистам, которых пытался переманить
06.12.2025 [17:46],
Павел Котов
Есть мнение, что путь к сердцу лежит через желудок. Видимо, этим тезисом решил руководствоваться и гендиректор Meta✴✴ Марк Цукерберг (Mark Zuckerberg), когда поставил цель привлечь в свою компанию лучших специалистов в области искусственного интеллекта — некоторым он лично привозил суп домашнего приготовления. 
Источник изображения: Mark Zuckerberg Об этом рассказал старший научный сотрудник OpenAI Марк Чэнь (Mark Chen). «Довольно интересно и забавно было смотреть, как всё со временем раскручивается. Знаете, есть ряд любопытных историй, как Цукерберг лично привозил суп людям, которых пытался у нас переманить», — рассказал он в недавнем интервью. Когда Чэнь услышал об этом, поступок Цукерберга поначалу его шокировал, но потом и OpenAI взяла этот приём на заметку. «Я тоже привозил суп людям, которых мы набирали из Meta✴✴», — признался он со смехом. Если у OpenAI постоянно кто-то пытается переманивать учёных и инженеров, значит, у неё сильные позиции в гонке ИИ. «Мы постоянно под атакой. Вот так становится ясно, что мы — лидер, да? Любая компания начинает [работать], откуда они начинают набирать сотрудников? В OpenAI. Им нужны знания экспертов, наше видение, наша философия мира. И это мы воспитали столько звёздных учёных, правда? Думаю, OpenAI как не кто иной сегодня создаёт имена в области ИИ», — отметил Марк Чэнь. Активнее всех проявила себя в этом деле Meta✴✴ — гигант соцсетей безуспешно пытался переманить «половину» прямых подчинённых Чэня, но лучших специалистов OpenAI удерживает «довольно успешно». Предлагаемая в Meta✴✴ зарплата для ведущих специалистов может исчисляться сотнями миллионов долларов, рассказал в июне глава OpenAI Сэм Альтман (Sam Altman) — в отдел Meta✴✴ Superintelligence Lab ушёл, в частности, один из создателей ChatGPT Шэнцзя Чжао (Shengjia Zhao). Рост числа пользователей ChatGPT стал замедляться, а Gemini набирает обороты
06.12.2025 [06:27],
Анжелла Марина
OpenAI столкнулась с первыми серьёзными признаками замедления посещаемости. Рост ChatGPT за последние месяцы едва превысил 6 %, тогда как Gemini, по данным аналитической компании Sensor Tower, увеличил аудиторию на 30 % и удвоил время, которое пользователи проводят в приложении. 
Источник изображения: OpenAI По состоянию на ноябрь 2025 года ChatGPT остаётся лидером на рынке ИИ-чатов-ботов с 50 % глобальных загрузок на мобильные устройства и 55 % ежемесячной активной аудитории. Однако темпы его роста стали резко снижаться, указывая на возможное приближение к насыщению рынка, сообщает TechCrunch. В то же время Google Gemini продемонстрировал рост ежемесячной активной аудитории, что эксперты связывают с запуском в сентябре новой модели генерации изображений Nano Banana. Кроме того, пользователи стали проводить в приложении Gemini значительно больше времени: с марта по ноябрь этот показатель вырос на 120 % и достиг в среднем 11 минут в день, тогда как у пользователей ChatGPT он снизился на 10 % в ноябре по сравнению с июлем. 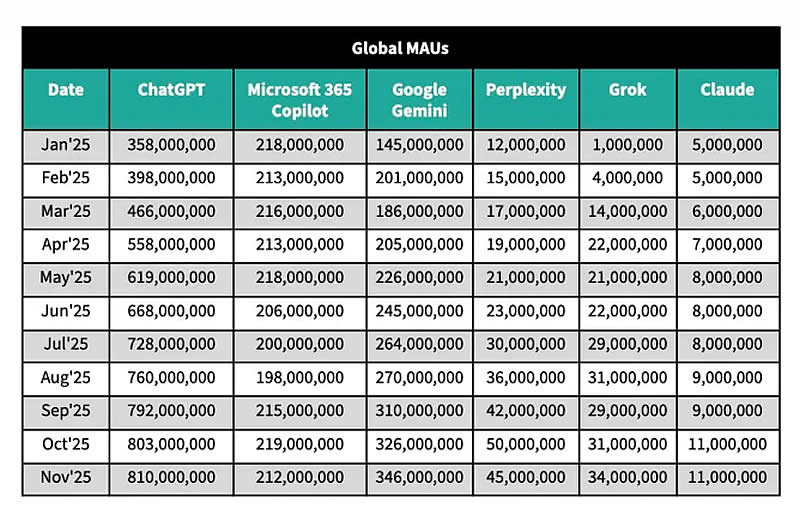
Источник изображения: Sensor Tower 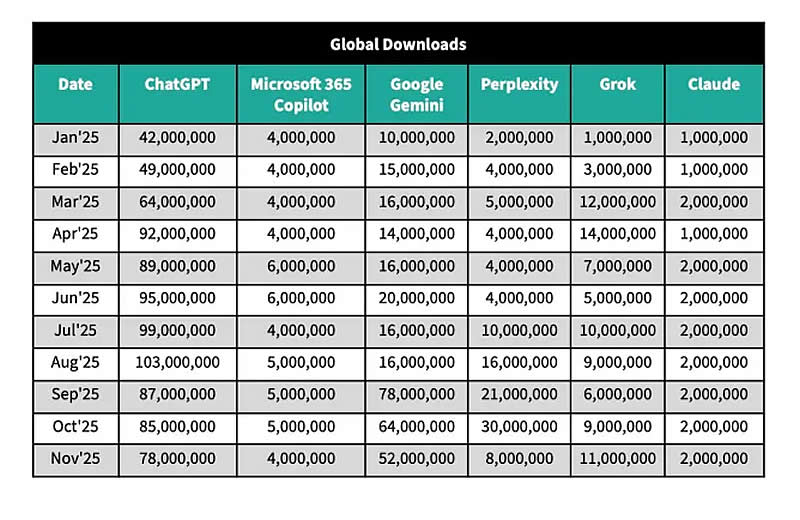
Источник изображения: Sensor Tower Преимущество Gemini, по мнению аналитиков, заключается в его глубокой интеграции в операционную систему Android. Так, по данным Sensor Tower, в США пользователи Android в два раза чаще взаимодействуют с Gemini напрямую через ОС, а не через отдельное мобильное приложение, что даёт Google дополнительные рычаги влияния на глобальном рынке, где Android доминирует. За последние семь месяцев (май–ноябрь 2025 года) доля Gemini в общей аудитории всех основных ИИ-чатов, включая ChatGPT, Copilot, Claude, Perplexity и Grok, выросла на три процентных пункта, тогда как доля ChatGPT сократилась на столько же за последние четыре месяца. Perplexity и Claude показали в 2025 году трёхзначный рост своей аудитории — на 370 % и 190 % в годовом выражении соответственно. Глобальные загрузки ChatGPT выросли на 85 % к ноябрю в годовом исчислении, но этот показатель отстаёт от среднего роста по группе в целом, составляющего 110 %. Лидерами по росту загрузок стали Perplexity (215 %) и Gemini (190 %). Apple теряет топ-менеджеров, а таланты бегут к ИИ-конкурентам — Куку предстоит самый трудный экзамен в карьере
05.12.2025 [20:41],
Сергей Сурабекянц
За последние 12 месяцев Apple покинули четыре ведущих менеджера, к конкурентам также перешли десятки сотрудников рангом пониже. По мнению аналитиков, эти увольнения лишь подчёркивают назревшие перемены в компании. Остающемуся пока у руля Apple Тиму Куку (Tim Cook) и его новым коллегам предстоит серьёзное испытание — подготовить компанию к эпохе искусственного интеллекта и волне совершенно новых конкурентных устройств, которая последует за этим. В июле объявил о своей отставке главный операционный директор Apple, а финансовый директор компании перешёл на новую должность в конце прошлого года. В понедельник Apple объявила об уходе руководителя по стратегии в области искусственного интеллекта. В среду ведущий дизайнер перешёл в Meta✴✴. В четверг компания объявила, что её главный юрисконсульт и руководитель отдела политики уйдут в отставку в следующем году. Согласно обзору профилей в LinkedIn, за последние месяцы десятки инженеров и дизайнеров Apple, специализирующихся на аудио, дизайне часов, робототехнике и других областях, перешли в конкурирующие компании OpenAI и Meta✴✴. Это часть долгосрочной «утечки мозгов», которая лишает компанию ключевых новаторов и даёт конкурентам опыт, который они надеются использовать в противостоянии с Apple. На этой неделе глава Meta✴✴ Марк Цукерберг (Mark Zuckerberg) нанял Алана Дая (Alan Dye), бывшего ведущего разработчика Apple. Ранее он переманил нескольких ключевых специалистов Apple по ИИ. После провала его попытки создать метавселенную, которая вытеснила бы привычные iPhone, он сделал ставку на ИИ и умные очки. В июле 2025 года компания OpenAI официально закрыла сделку по поглощению io — стартапа, специализирующегося на разработке устройств, одним из учредителей которого являлся бывший дизайнер Apple Джони Айв (Jony Ive). Сумма сделки составила около $6,5 млрд. При помощи Айва OpenAI планирует создать прорывное устройство на базе ИИ, которое составит конкуренцию iPhone. Илон Маск (Elon Musk) не раз высказывал возмущение доминированием Apple и даже заявлял о возможной разработке собственного устройства на замену iPhone. Его компания X подала в суд на Apple из-за недовольства размещением собственного приложения на основе искусственного интеллекта в App Store. На сегодняшний день непосредственной угрозы рыночному успеху iPhone со стороны всех этих разработчиков искусственного интеллекта не просматривается. Пока не существует ни одного полноценного приложения на основе ИИ, которое позволило бы перенестись в цифровое пространство, ни тем более устройства, которое бы это предлагало. Однако без собственной последовательной стратегии в области ИИ, способной убедить клиентов и сотрудников в том, что компания может играть значимую роль в разработке определяющей технологии десятилетия, Apple оставляет другим компаниям огромное пространство для конкуренции. Если Куку удастся создать успешные продукты на основе ИИ до своего ухода, он сможет сохранить за собой статус одного из величайших руководителей в сфере технологий, одновременно обеспечив своему преемнику хороший старт. ИИ-модели готовы признаться в своих грешках, показало исследование OpenAI
05.12.2025 [18:21],
Павел Котов
Исследователи OpenAI в поисках эффективных методов аудита моделей искусственного интеллекта, склонных выдавать нежелательные результаты или пытаться обмануть пользователей, обнаружили, что эти модели вполне способны к признаниям в собственном ненадлежащем поведении. 
Источник изображения: Igor Omilaev / unsplash.com В своём исходном значении понятие «признания», конечно, неприменимо к моделям ИИ, которые в действительности представляют собой не более чем сложные статистические алгоритмы. В терминах OpenAI под «признанием» понимается возможность модели оценить свои нежелательные действия, например, галлюцинации в ответах или попытки нарушить условия задачи, чтобы прийти к желаемому результату. «Признание — это [вторичный] ответ, даваемый по запросу после первоначального ответа модели, призванный служить полным отчётом о соответствии модели букве и духу её политик и инструкций», — говорится в статье (PDF) OpenAI. Проще говоря, модели отправляется запрос на получение второго ответа с оценкой первого. Склонность к неподобающему поведению у ИИ формируется на этапе обучения с подкреплением, когда он обнаруживает возможность злоупотреблять механизмами вознаграждения. То есть модель исходит из того, что получит вознаграждение за «признание» и останется безнаказанной за сами нежелательные действия, например, за подхалимство. Эти соображения, как оказалось, подтверждаются на практике. В 11 из 12 проведённых тестов она признавалась минимум в половине случаев, когда действовала вопреки инструкциям. Частота признаний оказалась переменчивой величиной: средняя вероятность получить признание по всем тестам составила 74,3 %. В 4 тестах из 12 этот показатель был выше 90 %, а в 2 из 12 — 50 % или ниже. Вероятность ложноотрицательного ответа, когда модель нарушила правила и не признала своей ошибки, составила лишь 4,4 %; были и ложноположительные, когда модель признавалась в неподобающем поведении, хотя ничего такого не совершала. Когда OpenAI включили сценарий с «признаниями» в механизм обучения модели, качество её ответов не показало существенного ухудшения. С другой стороны, даже «признаваясь» в своих грехах, она стала вести себя не лучше, но хотя бы честнее. То есть «признание» — это не заградительный барьер, а механизм безопасности, который к тому же работает с переменным успехом. OpenAI проиграла в суде битву за бренд io — под ним собирались выпускать загадочные ИИ-гаджеты от Айва
05.12.2025 [11:34],
Владимир Мироненко
Апелляционный суд девятого округа США отказал OpenAI в удовлетворении её апелляции по поводу решения суда нижестоящей инстанции касательно прав на торговую марку io. Это означает, что OpenAI по-прежнему запрещено использовать брендинг io для продвижения будущих устройств, которые могут быть похожи на продукты компании iyO, отстаивающей права на торговую марку. 
Источник изображения: Levart_Photographer/unsplash.com OpenAI приобрела стартап io по производству ИИ-устройств, основанную бывшим главным дизайнером Apple Джони Айвом (Jony Ive), в мае этого года. Ещё ничего не выпустив, стартап столкнулся с проблемами, поскольку компания Iyo, занимающаяся разработкой слуховых аппаратов, подала на него в суд в связи с неправомерным использованием io. В связи с этим OpenAI пришлось убрать в блоге упоминания о сделке и сотрудничестве с io. Согласно пресс-релизу iyO, апелляционный суд удовлетворил её иск по следующим пунктам:
Ресурс 9to5mac.com сообщил, что после решения апелляционного суда дело, вероятно, будет передано в окружной суд для проведения слушаний по вынесению предварительного запрета, который либо оставит ограничения в силе, либо сузит или расширит их. Судебная система работает крайне медленно. Слушания о предварительном судебном запрете состоятся в апреле 2026 года, а раскрытие фактов и экспертиз, рассмотрение ходатайств и рассмотрение дела с участием присяжных пройдут в 2027 и 2028 годах. OpenAI поглотит ИИ-стартап Neptune — это поможет в обучении новых ИИ-моделей
04.12.2025 [14:04],
Алексей Разин
Претендуя на всеобщее внимание и безраздельное доверие инвесторов, компания OpenAI уже не стесняется делать приобретения активов, которые могут помочь ей в развитии бизнеса. Например, стартап Neptune, который предлагал разработчикам систем искусственного интеллекта инструменты для мониторинга за обучением языковых моделей, будет продан OpenAI. 
Источник изображения: Neptune Сумма сделки не раскрывается, но издание The Information со ссылкой на неофициальные источники сообщает, что OpenAI передаст по её условиям владельцам Neptune менее $400 млн в форме собственных акций. Для OpenAI деятельность Neptune является хорошо знакомым бизнесом, поскольку первая из компаний является клиентом второй. К числу таких клиентов можно отнести Samsung, Roche и HP. Изначально деятельность Neptune осуществлялась под крылом Deepsense, но в 2018 году первая обрела самостоятельность. К настоящему моменту Neptune удалось привлечь $18 млн на финансирование своей деятельности. Для сравнения, капитализацию OpenAI сейчас оценивают более чем в $500 млрд, поэтому для неё передача количества акций, эквивалентных сумме $400 млн, не станет большой жертвой в обмен на ценный актив, который можно использовать в работе. Хотя официальные представители OpenAI отрицают факт подготовки к выходу на биржу, слухи приписывают стартапу намерения сделать соответствующий шаг во второй половине следующего года. Капитализация OpenAI по итогам этих мероприятий может вырасти до $1 трлн. Сделка с Neptune не станет для OpenAI первой стратегической инвестицией. Ранее она уже вложилась в капитал Thrive Holdings с прицелом внедрить ИИ в сфере бухгалтерского учёта и услуг в области информационных технологий. В ChatGPT появилась реклама — даже у пользователей самого дорогого тарифа за $200 в месяц
04.12.2025 [13:18],
Павел Котов
В минувшие выходные OpenAI начала без громких анонсов показывать в тестовом режиме рекомендации сторонних приложений в чатах — они появились преимущественно у пользователей, которые оформили дорогую подписку ChatGPT Pro за $200 в месяц. 
Источник изображения: BoliviaInteligente / unsplash.com Реакция последовала незамедлительно, как только в соцсетях опубликовали первый снимок экрана с такой рекламой — высказывается мнение, что OpenAI придётся отступить, чтобы сохранить преданную аудиторию. Одному из пользователей ChatGPT Pro сервис предложил «подыскать групповое занятие фитнесом» и подключить приложение Peloton — он не спрашивал искусственный интеллект ни о Peloton, ни о фитнесе вообще. Ранее в приложении ChatGPT для Android обнаружили фрагменты кода с упоминанием «рекламной функции», некоего «базарного контента» (bazaar content), «поисковой рекламы» и «карусели с поисковой рекламой». 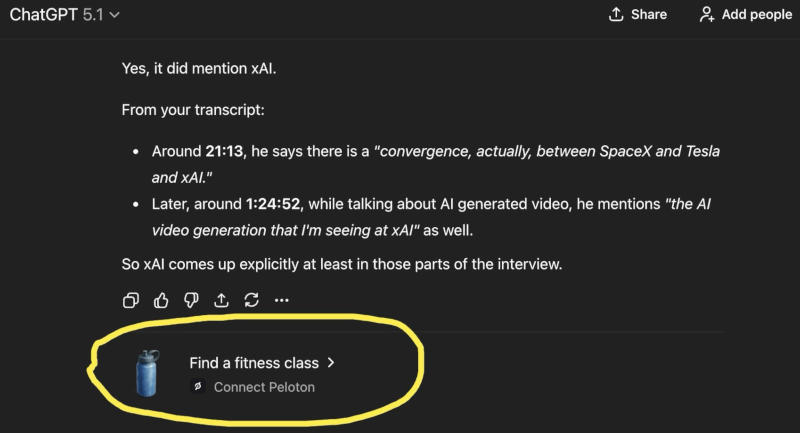
Источник изображения: x.com/Yuchenj_UW Появление рекламы в ChatGPT было ожидаемым нововведением, особенно для пользователей, у которых нет платной подписки, но её показ обладателям дорогой подписки ChatGPT Pro за $200 в месяц — это, пожалуй, перебор. Как впрочем, и тем, кто платит $20 в месяц за ChatGPT Plus. Один из пользователей ChatGPT Pro заявил, что уже подумывает отменить платную подписку; второй, обладатель такой же, сообщил, что видит её уже два или три дня, и добавил, что он из Великобритании — значит, OpenAI решила провести свой эксперимент и там. Пользователи ChatGPT сошлись во мнении, что показ объявлений, не имеющих отношения к теме переписки с чат-ботом, явно трактуется как реклама. Хотя дизайнерам, например, подошло бы предложение подключить сервис Canva. Неизвестно, решит ли OpenAI оставить такой формат для всё аудитории, но хотелось бы надеяться, что отрицательных последствий для всей отрасли ИИ это не повлечёт. Сэм Альтман пытался заполучить амбициозного конкурента SpaceX — вероятно, ради орбитальных дата-центров
04.12.2025 [11:58],
Алексей Разин
Амбиции одного из основателей OpenAI Сэма Альтмана (Sam Altman), который его сейчас возглавляет, очевидным образом простираются за пределы сегмента искусственного интеллекта. С подачи The Wall Street Journal стало известно, что Альтман рассматривал возможность покупки или вложения средств в капитал аэрокосмической компании Stoke Space. Сделка в итоге не состоялась, но сам факт её подготовки интригует. 
Источник изображения: SpaceX Cтартап Stoke Space был основан выходцами из Blue Origin, он специализируется на разработке полностью многоразовых ракет-носителей, тем самым позиционируя себя в качестве потенциального конкурента SpaceX Илона Маска (Elon Musk). Как известно, Маск на ранних этапах поддерживал OpenAI и участвовал в развитии этого стартапа, но противоречия с Альтманом заставили его создать собственный стартап xAI, который позже номинально объединился с социальной сетью X (бывшей Twitter). По замыслу Альтмана, ему должен был достаться контрольный пакет акций Stoke Space, но переговоры не привели к сделке. Принято считать, что главе OpenAI собственная аэрокосмическая компания могла бы пригодиться для создания космических центров обработки данных, которые не занимали бы место на нашей планете и питались бы бесплатной солнечной энергией. Альтман уже поддерживает аэрокосмический стартап Longshot Space, который разрабатывает инновационную технологию вывода спутников на орбиту. Аэрокосмической сферой личное соперничество Альтмана с Маском не ограничивается, поскольку первый также поддерживает стартап Merge Labs, разрабатывающий устройство для трансляции мозговых импульсов в компьютер без необходимости вживлять его в черепную коробку человека. Конкурирующей компанией Илона Маска является Neuralink. Наконец, OpenAI не противится идее создания собственной социальной сети, которая конкурировала бы с X. По сути, единственные сферы, в которых Альтман не бросает вызов Маску — это производство электромобилей и строительство подземных туннелей транспортного назначения. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex